
The Python Proficiency Playbook: From Clean Code to Scalable Systems
Code Like a Dev. Think Like an Engineer.

Unlock the secrets of becoming an advanced Python developer with The Python Proficiency Playbook—a step-by-step guide designed for engineers who want more than just syntax skills. In this episode, we break down:
What it truly means to be Python-proficient
How to think architecturally and build scalable applications
Mastering Pythonic idioms and modern concurrency
Leveraging professional dev tools (version control, testing, linters)
A complete end-to-end project that fuses all skills into one production-grade build
Timeless engineering principles + how to adapt to trends like AI & distributed systems
This is not just a tutorial—it's a mindset shift. Whether you're preparing for a senior dev role or building large-scale AI apps, this guide is your roadmap.
👇 Don't forget to like, subscribe, and share with fellow Pythonistas!
The Python Proficiency Playbook: From Foundational Mastery to Production-Grade Systems
Introduction: Beyond Syntax – What "Strong Proficiency" in Python Truly Means
In the world of software development, the term "proficiency" is often misconstrued as simply knowing the syntax of a programming language. However, for a language as dynamic and powerful as Python, true mastery extends far beyond its basic constructs. "Strong proficiency" is not a measure of how many language features one can recite, but rather a holistic competency that combines deep language fluency with architectural thinking and rigorous engineering discipline. It signifies the ability to not just write code, but to architect, build, and deploy robust, scalable, and maintainable software systems that solve real-world problems effectively. A proficient Python developer understands that the code itself is only one component of a much larger ecosystem of tools, practices, and principles that ensure software quality and reliability.
This guide is designed as a comprehensive roadmap for the developer who has moved past the initial learning curve and now asks, "What's next?" It is for the ambitious individual seeking to bridge the gap between writing simple scripts and architecting complex, production-grade applications. The journey is structured into four distinct parts. Part 1 focuses on achieving fluency in the language, embracing the "Pythonic" way of thinking that prioritizes clarity and elegance. Part 2 delves into the advanced concepts and theoretical underpinnings, such as concurrency and algorithms, that govern system performance and scalability. Part 3 equips the developer with the professional toolchain and engineering practices—from project setup and testing to deployment—that are non-negotiable in a modern software environment. Finally, Part 4 synthesizes all these skills into a practical, end-to-end project, demonstrating how to apply these concepts to build a real-world, production-ready application.
This playbook is more than a collection of tips; it is a structured curriculum for transforming from a coder into a software engineer. By navigating this path, developers will acquire the skills necessary to not only contribute to but also lead the development of sophisticated Python applications.
Part 1: Mastering the Pythonic Way – The Foundation of Excellence
The first significant step in elevating one's Python skills is to transition from writing code that merely works to writing code that is expressive, efficient, and idiomatic. This "Pythonic" approach is not just about aesthetics; it is about leveraging the language's design philosophy and its highly optimized features to produce code that is more readable, maintainable, and often more performant. This foundation of excellence is what separates a novice from a proficient practitioner.
1.1 Writing Idiomatic Python: The Art of "Pythonic" Code
The Zen of Python, an easter egg accessible by typing import this into a Python interpreter, offers guiding principles like "Beautiful is better than ugly" and "Simple is better than complex." These aphorisms capture the essence of Pythonic code. It is a style that favors clarity and conciseness, often achieving complex tasks with surprisingly simple syntax.
List and Dictionary Comprehensions
One of the most common anti-patterns for developers coming from other languages is the manual construction of lists using for loops. While functional, this approach is verbose and fails to leverage one of Python's most powerful features.
Consider creating a list of squares from 0 to 9. A traditional loop would look like this:
Python
squares =
for i in range(10):
squares.append(i * i)
# squares is now
A list comprehension achieves the same result in a single, expressive line:
Python
squares = [i * i for i in range(10)]
# squares is now
This is not merely syntactic sugar. List comprehensions are often faster than their for loop counterparts because they are optimized at the C-level in the Python interpreter and avoid the overhead of repeated .append() method calls. This pattern extends to dictionaries and sets and can include conditional logic for filtering. For instance, to create a dictionary of even numbers and their squares:
Python
even_squares = {i: i * i for i in range(10) if i % 2 == 0}
# even_squares is {0: 0, 2: 4, 4: 16, 6: 36, 8: 64}
Mastering comprehensions is a fundamental step toward writing efficient and Pythonic code.
Generator Expressions
While list comprehensions are powerful, they build the entire list in memory at once. For very large datasets, this can be memory-intensive. Generator expressions provide a memory-efficient alternative by creating an iterator that yields items one at a time, on demand. They use parentheses instead of square brackets:
Python
# A list comprehension - builds the entire list in memory
large_list = [i for i in range(1_000_000)]
# A generator expression - creates an iterator, no list is built
large_generator = (i for i in range(1_000_000))
The generator expression is ideal for iterating over large sequences, such as lines in a massive file or a stream of data, as it only ever holds one item in memory at a time. This distinction is crucial for writing scalable, memory-conscious applications.
The with Statement and Context Managers
Proper resource management—such as ensuring files are closed, database connections are released, or locks are acquired and released—is critical for robust applications. A common but verbose pattern is the try...finally block, which guarantees that cleanup code in the finally block is executed, regardless of whether an error occurred in the try block.
The with statement provides a much cleaner and more reliable way to manage resources by abstracting this pattern away through context managers. A context manager is any object that implements the context management protocol, which consists of the
__enter__() and __exit__() methods.
The most common example is file handling:
Python
# The with statement ensures the file is closed automatically
with open('data.txt', 'r') as f:
content = f.read()
# No need to call f.close()
This is equivalent to, but far more concise than, the try...finally block. Developers can create their own context managers in two ways:
Class-based Context Managers: By defining a class with
__enter__()and__exit__()methods.__enter__handles setup, and__exit__handles teardown.Python
import time
class Timer:
def __enter__(self):
self.start_time = time.time()
return self
def __exit__(self, exc_type, exc_val, exc_tb):
self.end_time = time.time()
self.elapsed_time = self.end_time - self.start_time
print(f"Block executed in: {self.elapsed_time:.4f} seconds")
# Return False to propagate exceptions, True to suppress them
with Timer():
# Some long-running operation
_ = [i**2 for i in range(1000000)]
Function-based Context Managers: Using the
@contextmanagerdecorator from thecontextlibmodule, which is often simpler for basic setup/teardown logic.Python
from contextlib import contextmanager
@contextmanager
def timer():
start_time = time.time()
try:
yield
finally:
end_time = time.time()
elapsed_time = end_time - start_time
print(f"Block executed in: {elapsed_time:.4f} seconds")
with timer():
# Some long-running operation
_ = [i**2 for i in range(1000000)]
Understanding and using context managers is a sign of a developer who thinks about resource safety and code clarity.
1.2 Advanced Functional and Metaprogramming Concepts
Beyond idiomatic syntax, proficiency in Python involves understanding its more advanced capabilities for modifying and extending behavior at runtime. Decorators and metaclasses are two such powerful features, typically used in frameworks and libraries to reduce boilerplate and add functionality in a clean, reusable way.
Decorators: Extending Functionality Without Modification
Decorators are a prime example of Python's support for higher-order functions—functions that can take other functions as arguments and return them. A decorator is a function that takes another function and extends its behavior without explicitly modifying it. This design pattern is invaluable for separating cross-cutting concerns (like logging, timing, or authentication) from the core business logic of a function.
The @ syntax is syntactic sugar that makes applying decorators clean and readable. For example, the following two snippets are equivalent:
Python
# Using the @ syntax
@my_decorator
def say_hello():
print("Hello!")
# The equivalent manual application
def say_hello():
print("Hello!")
say_hello = my_decorator(say_hello)
A practical example is a @timer decorator to measure the execution time of a function:
Python
import time
import functools
def timer(func):
@functools.wraps(func) # Preserves the original function's metadata
def wrapper_timer(*args, **kwargs):
start_time = time.perf_counter()
value = func(*args, **kwargs)
end_time = time.perf_counter()
run_time = end_time - start_time
print(f"Finished {func.__name__!r} in {run_time:.4f} secs")
return value
return wrapper_timer
@timer
def waste_some_time(num_times):
for _ in range(num_times):
sum([i**2 for i in range(1000)])
waste_some_time(1)
waste_some_time(999)
Here, functools.wraps is used to preserve the original function's name and docstring, which is a crucial best practice. Decorators are used extensively in web frameworks like Flask and FastAPI for routing (@app.route('/')) and in many other libraries for tasks like caching results or enforcing access control.
Metaclasses: The Class of a Class
Metaclasses are one of Python's most advanced and often misunderstood features. In Python, everything is an object, including classes themselves. A metaclass is the "class" of a class; it defines how a class is created. The default metaclass for all classes in Python is
type.
Just as a class is a blueprint for creating instances (objects), a metaclass is a blueprint for creating classes. The type() function can be used not only to check an object's type but also to create classes dynamically :
Python
# Dynamically creating a class named MyClass with an attribute 'x'
MyClass = type('MyClass', (object,), {'x': 100})
# Creating an instance of the dynamically created class
instance = MyClass()
print(instance.x) # Output: 100
While dynamic class creation is useful, the real power comes from creating custom metaclasses by subclassing type. This allows you to intercept the class creation process and modify the class before it is even created. A common (though often debated) use case is implementing the Singleton pattern, which ensures that only one instance of a class is ever created.
Python
class SingletonMeta(type):
_instances = {}
def __call__(cls, *args, **kwargs):
if cls not in cls._instances:
instance = super().__call__(*args, **kwargs)
cls._instances[cls] = instance
return cls._instances[cls]
class DatabaseConnection(metaclass=SingletonMeta):
def __init__(self):
print("Creating new database connection instance.")
# Usage
db1 = DatabaseConnection() # Prints "Creating new database connection instance."
db2 = DatabaseConnection() # Does not print, returns the existing instance
print(db1 is db2) # Output: True
Metaclasses are a tool for advanced metaprogramming, typically found in the internals of frameworks like Django (for its ORM) or SQLAlchemy. For most application-level development, they are overkill and can make code harder to understand and maintain. A proficient developer knows not only how to use them but, more importantly, when to use them—which is rarely.
Part 2: Building for Performance and Scale – Advanced Concepts in Action
Writing elegant, Pythonic code is the first step. The next is understanding the principles that govern how that code performs under load. A proficient engineer does not treat performance as an afterthought; they make architectural decisions based on a solid understanding of concurrency models, data structures, and algorithmic complexity. These choices are not mere technical details—they are fundamental to building systems that are both fast and scalable.
2.1 Concurrency and Parallelism Demystified
For applications that need to handle multiple tasks simultaneously, Python offers several concurrency models. The choice between them is one of the most critical architectural decisions a developer will make, and it hinges on a deep understanding of the task's nature (I/O-bound vs. CPU-bound) and a single, infamous feature of the CPython interpreter: the Global Interpreter Lock (GIL).
The Core Problem: The Global Interpreter Lock (GIL)
The Global Interpreter Lock, or GIL, is a mutex that protects access to Python objects, preventing multiple native threads from executing Python bytecode at the same time within a single process. Even on a multi-core processor, only one thread can be executing Python code at any given moment. The GIL exists to simplify memory management in CPython and prevent race conditions when accessing Python objects from multiple threads.
This has a profound implication: for CPU-bound tasks (operations that are computationally intensive, like complex mathematical calculations or data processing), using multiple threads in Python will not result in true parallelism and can even make the program slower due to the overhead of context switching between threads that are all competing for the same lock.
However, for I/O-bound tasks (operations that spend most of their time waiting for input/output, such as network requests, database queries, or disk reads/writes), the GIL is less of a bottleneck. When a thread initiates an I/O operation, it releases the GIL, allowing other threads to run while it waits for the operation to complete. This enables concurrency, though not true parallelism.
This distinction is the key to choosing the correct concurrency model. A developer who misunderstands the GIL might, for example, try to speed up a heavy data processing task by spreading it across multiple threads, only to find the performance has worsened. A proficient developer first analyzes the bottleneck—is the program waiting for the network, or is it crunching numbers?—and then selects the appropriate tool for the job.
Threading (threading): Concurrency for I/O-Bound Tasks
Python's threading module is the traditional tool for I/O-bound concurrency. Because threads release the GIL during blocking I/O calls, it is an effective way to perform multiple network requests or file operations concurrently, dramatically reducing the total execution time compared to a sequential approach.
The modern way to manage threads is with the concurrent.futures.ThreadPoolExecutor, which provides a high-level interface for managing a pool of worker threads.
Example: Concurrent Web Page Downloads
Python
import requests
import concurrent.futures
import time
urls = [
"https://www.python.org/",
"https://www.google.com/",
"https://www.github.com/",
"https://www.microsoft.com/",
"https://www.amazon.com/",
]
def download_url(url):
try:
requests.get(url)
return f"Successfully downloaded {url}"
except requests.RequestException as e:
return f"Failed to download {url}: {e}"
start_time = time.time()
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
results = executor.map(download_url, urls)
for result in results:
print(result)
end_time = time.time()
print(f"Total time (threaded): {end_time - start_time:.2f} seconds")
In this example, all five download requests are initiated nearly simultaneously. While one thread waits for a response from python.org, another can be sending a request to google.com, making efficient use of waiting time.
Parallelism (multiprocessing): The Solution for CPU-Bound Tasks
To achieve true parallelism and leverage multiple CPU cores for computationally intensive tasks, a developer must use the multiprocessing module. This module bypasses the GIL by creating separate processes, each with its own Python interpreter and memory space.
Similar to threading, the concurrent.futures.ProcessPoolExecutor provides a convenient way to manage a pool of worker processes.
Example: Parallel Fibonacci Calculation
Python
import concurrent.futures
import time
def fib(n):
if n <= 1:
return n
return fib(n-1) + fib(n-2)
numbers = [1, 2, 3, 4]
# Sequential execution
start_time = time.time()
for num in numbers:
fib(num)
end_time = time.time()
print(f"Total time (sequential): {end_time - start_time:.2f} seconds")
# Parallel execution
start_time = time.time()
with concurrent.futures.ProcessPoolExecutor() as executor:
executor.map(fib, numbers)
end_time = time.time()
print(f"Total time (parallel): {end_time - start_time:.2f} seconds")
On a multi-core machine, the parallel version will be significantly faster because the fib function, a classic CPU-bound task, is executed simultaneously in different processes, each on a separate core. The trade-off is higher memory usage and more complex inter-process communication compared to threads.
Asynchronous Programming (asyncio): High-Throughput I/O
For applications that need to handle a massive number of I/O-bound connections (e.g., web servers, chat applications, database proxies), asyncio is the modern, preferred solution. It uses a single-threaded event loop and a concept called cooperative multitasking.
Instead of relying on the OS to switch between threads, asyncio tasks (coroutines, defined with async def) explicitly yield control back to the event loop when they encounter an I/O operation (marked with await). The event loop can then run other tasks that are ready, rather than waiting.
The key advantage of asyncio over threading is its scalability. OS threads are relatively heavyweight resources; creating thousands of them can exhaust system memory. asyncio tasks, on the other hand, are extremely lightweight, allowing a single thread to efficiently manage tens of thousands of concurrent connections.
Example: A Simple asyncio Web Server
Python
import asyncio
async def handle_client(reader, writer):
data = await reader.read(100)
message = data.decode()
addr = writer.get_extra_info('peername')
print(f"Received {message!r} from {addr!r}")
writer.write(data)
await writer.drain()
print("Closing the connection")
writer.close()
async def main():
server = await asyncio.start_server(
handle_client, '127.0.0.1', 8888)
addr = server.sockets.getsockname()
print(f'Serving on {addr}')
async with server:
await server.serve_forever()
asyncio.run(main())
This server can handle many simultaneous client connections within a single thread, making it incredibly efficient for I/O-heavy workloads.
Table 1: Python Concurrency Model Decision Matrix
To provide a clear, actionable guide, the following table summarizes the key characteristics and ideal use cases for each concurrency model. This decision matrix is a critical tool for any developer architecting a concurrent system in Python.
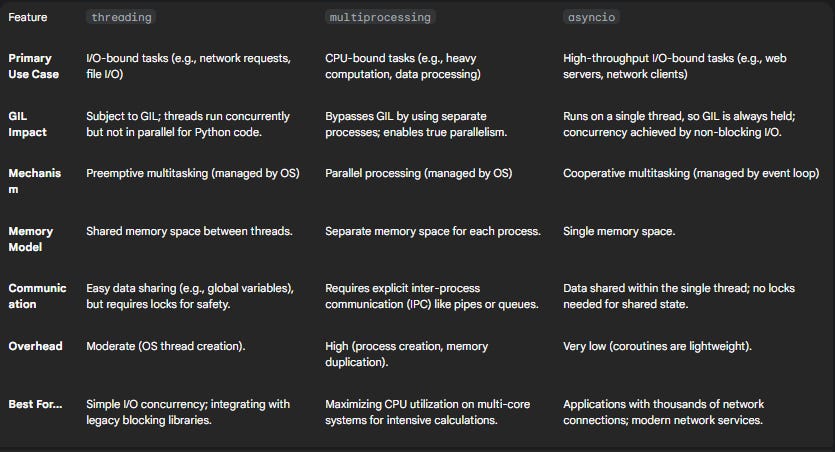
2.2 Data Structures & Algorithms for the Real World
A proficient engineer understands that data structures and algorithms (DSA) are not just topics for coding interviews; they are the fundamental building blocks of efficient systems. The choice of a data structure for a core component of a system directly impacts its performance, memory usage, and scalability. Similarly, the algorithmic paradigm used to process data determines how the system will behave as the data volume grows.
Data Structures: The Architectural Impact of Choice
While basic data structures like arrays and linked lists are well-understood, the critical skill is knowing the trade-offs between more advanced structures in a system design context. For example, when designing a database indexing system, a developer might choose between a hash table and a balanced binary search tree (like a B-Tree).
Hash Table (Dictionary in Python): Offers average-case O(1) time complexity for insertions, deletions, and lookups. This makes it extremely fast for key-value lookups, such as retrieving a user profile by
user_id. This is why hash tables are frequently used for implementing caches. However, hash tables do not store data in any particular order, making range queries (e.g., "find all users who signed up in May") inefficient, as they would require a full scan of the data.Balanced Binary Search Tree (e.g., B-Tree): Offers O(logn) time complexity for insertions, deletions, and lookups. While slightly slower for direct lookups than a hash table, its crucial advantage is that it maintains data in a sorted order. This makes it highly efficient for range queries and ordered traversals, which is a fundamental requirement for most relational database indexes.
The choice, therefore, is not about which is "better" but which best serves the system's access patterns. A proficient developer analyzes the system's requirements—Does it need fast point queries? Does it need ordered data?—and selects the data structure that optimizes for those requirements.
Algorithmic Paradigms in Practice: Greedy vs. Dynamic Programming
Understanding different algorithmic strategies is key to solving optimization problems efficiently. Two of the most important—and often confused—paradigms are the greedy approach and dynamic programming. Both are applicable to problems that exhibit optimal substructure, meaning that an optimal solution to the problem contains within it optimal solutions to subproblems. Their difference lies in how they construct that optimal solution.
Greedy Approach: A greedy algorithm makes the choice that seems best at the moment—the "locally optimal" choice—in the hope that it will lead to a globally optimal solution. It never reconsiders its choices. This approach is simple and fast but only works for problems with the "greedy choice property," where a local optimum is guaranteed to be part of a global optimum.
Example: The Fractional Knapsack Problem. A thief can take fractions of items. The greedy strategy is to take as much as possible of the item with the highest value-per-weight. This strategy is proven to yield the optimal solution.
Dynamic Programming (DP): A dynamic programming algorithm is more exhaustive. It solves a problem by breaking it down into simpler, overlapping subproblems. It solves each subproblem only once and stores its solution (a technique called memoization or tabulation). When making a decision, it considers the results of these subproblems to make a globally optimal choice.
Example: The 0-1 Knapsack Problem. A thief must take whole items or leave them. The greedy strategy of taking the most valuable item per weight first can fail. For example, a high-value-per-weight item might be very heavy, preventing the thief from taking other, smaller items that would have resulted in a higher total value. DP solves this by building up a table of optimal solutions for all possible sub-knapsack capacities, ensuring the final choice is globally optimal.
Proficiency here means recognizing the structure of a problem and determining whether a simple, fast greedy approach is sufficient or if the more robust, but often more complex, dynamic programming approach is required.
Big O Notation and Performance
Finally, a deep understanding of Big O notation is non-negotiable for predicting how a system will scale. An algorithm with
O(n2) complexity might be acceptable for a small dataset, but it will quickly become a bottleneck as the input size (n) grows. In system design, every critical operation—from a database query to an API response—must be analyzed for its time and space complexity. This analysis allows engineers to identify potential performance hotspots and design systems that remain responsive and efficient at scale.
Part 3: The Professional's Toolkit – Engineering for Production
A truly proficient Python developer understands that the code they write is only one piece of a larger puzzle. The ecosystem of tools and practices surrounding that code is what enables the creation of professional, reliable, and maintainable software. This section details the essential scaffolding of a production-grade project, covering everything from project setup and dependency management to automated testing and deployment pipelines. Mastering this toolkit is what elevates a developer from a solo coder to a valuable member of a high-performing engineering team.
3.1 Blueprint for Success: Modern Project Structure and Dependency Management
A well-organized project is easier to navigate, test, and package. The conventions and tools for structuring Python projects have evolved significantly, moving towards a standardized, declarative approach that enhances reproducibility and reduces ambiguity.
The src Layout
A widely recommended best practice for structuring a Python project is the src layout. In this structure, all of the application's source code resides within a
src directory at the root of the project.
my_project/
├── src/
│ └── my_package/
│ ├── __init__.py
│ └── module.py
├── tests/
│ └── test_module.py
├── pyproject.toml
└── README.md
This layout has two key advantages:
Clarity: It explicitly separates the source code from other project files like tests, documentation, and configuration.
Installability: It prevents accidental imports of the package from the current working directory. When running tests, the package must be installed (e.g., in editable mode with
pip install -e.), which ensures that the tests are running against the installed version of the code, just as it would be in a production environment.
pyproject.toml: The Single Source of Truth
For years, Python project configuration was fragmented across multiple files like setup.py, setup.cfg, and requirements.txt. This led to inconsistencies and potential security risks, as setup.py is an executable file. The modern standard, introduced in PEP 518, is the pyproject.toml file. This file uses the TOML (Tom's Obvious, Minimal Language) syntax to provide a single, declarative source of truth for project configuration.
A pyproject.toml file centralizes three key areas :
[build-system]: This mandatory section specifies the tools needed to build your project. It defines the build dependencies and the backend that tools likepipwill use.Ini, TOML
[build-system]
requires = ["setuptools>=61.0"]
build-backend = "setuptools.build_meta"
[project]: This section contains all the project's metadata, such as its name, version, description, authors, and dependencies. It replaces the need for asetup()call insetup.py.Ini, TOML
[project]
name = "my-package"
version = "0.1.0"
description = "A sample Python project."
requires-python = ">=3.8"
dependencies = [
"fastapi>=0.100.0",
"uvicorn>=0.23.0",
]
[project.optional-dependencies]
dev = [
"pytest",
"ruff",
"black",
]
[tool]: This section is a namespace for configuring third-party tools. Instead of having separate configuration files like.ruff.tomlor.black.toml, you can centralize their settings here, creating a cleaner project root.Ini, TOML
[tool.ruff]
line-length = 88
select = # Enable Flake8, Pyflakes, isort, flake8-bugbear
[tool.black]
line-length = 88
Adopting pyproject.toml is a hallmark of a modern Python developer, demonstrating an understanding of current best practices in packaging and tooling.
venv and pip: Isolated and Reproducible Environments
To prevent dependency conflicts between projects, it is essential to use virtual environments. Python's built-in venv module allows for the creation of lightweight, isolated Python environments, each with its own set of installed packages.
The standard workflow is as follows:
Create a virtual environment: From the project root, run the command. It is conventional to name the environment
.venv.Bash
python -m venv.venv
Activate the environment: Activation modifies the shell's
PATHto prioritize the virtual environment's executables.On macOS/Linux:
source.venv/bin/activateOn Windows:
.venv\Scripts\activate
Install dependencies: With the environment active, use
pipto install the dependencies defined inpyproject.toml. The-eflag installs the project in "editable" mode, which is ideal for development.Bash
pip install -e.[dev]
This command installs the project itself, its core dependencies, and the optional dependencies listed under the
[dev]group. This workflow ensures that every developer on a project, as well as the CI/CD pipeline, works with the exact same set of dependencies, guaranteeing reproducibility.
3.2 The Non-Negotiables: Version Control, Code Quality, and Testing
High-quality software is built through a process of continuous refinement and verification. This process is supported by a trinity of essential practices: version control to manage change, automated tools to enforce quality, and a robust test suite to validate correctness.
Effective Git Workflows
Git is the de facto standard for version control in software development. It allows teams to track changes, collaborate on code, and manage different versions of a project. While complex workflows exist, a simple and effective approach for most teams is the
feature-branching workflow:
The
mainbranch is always kept in a stable, deployable state.For any new feature or bug fix, a new branch is created from
main(e.g.,feature/add-user-auth).All work is done on this feature branch.
When the feature is complete and tested, a pull request (or merge request) is opened to merge the changes back into
main.The pull request is reviewed by other team members, and automated checks (like linting and testing) are run.
Once approved, the feature branch is merged into
main.
This workflow ensures that the main codebase remains clean and facilitates collaboration and code review.
Automating Code Quality with Ruff and Black
Manually enforcing code style and quality is tedious and error-prone. Modern Python development relies on automated tools to handle this.
Black: An "uncompromising code formatter" that automatically reformats Python code to a consistent style. Its opinionated nature eliminates debates about formatting, ensuring uniformity across the entire codebase.
Ruff: An "extremely fast Python linter" written in Rust. Ruff is a game-changer because it combines the functionality of many older tools—like Flake8 (linting), isort (import sorting), and pyupgrade (syntax modernization)—into a single, blazing-fast binary. Its speed makes it ideal for running on every file save and in CI pipelines without adding significant delay.
By configuring both tools in pyproject.toml and integrating them into the development workflow (e.g., via pre-commit hooks or editor integrations), teams can create a powerful, automated quality gate that ensures all committed code is both well-formatted and free of common errors.
Writing Robust Tests with pytest
Testing is not optional in professional software development; it is the primary mechanism for ensuring code correctness and preventing regressions. pytest has become the standard for testing in Python due to its simple syntax and powerful features.
Key pytest concepts that a proficient developer must master include:
Arrange-Act-Assert Model: A clear structure for tests. First, arrange the test setup. Second, act by calling the code under test. Third, assert that the outcome is as expected.
Assertion Introspection:
pytestuses Python's standardassertstatement. When an assertion fails,pytestrewrites the assertion to provide detailed output about the values involved, making debugging significantly faster and more intuitive than theself.assert...methods inunittest.Fixtures: Fixtures are functions decorated with
@pytest.fixturethat provide a fixed baseline for tests. They are used for setup and teardown logic, such as creating a database connection, initializing a class instance, or mocking an external service. Fixtures are injected into test functions by naming them as arguments, which makes test dependencies explicit and promotes reusability.Parametrization: The
@pytest.mark.parametrizedecorator allows a single test function to be run multiple times with different inputs and expected outputs. This drastically reduces code duplication for tests that follow the same logic but need to be validated against various scenarios.
A comprehensive test suite, written with pytest, gives developers the confidence to refactor code and add new features without fear of breaking existing functionality.
3.3 From Code to Cloud: The Deployment Pipeline
Writing and testing code locally is only half the battle. A proficient engineer must also understand how to package, deploy, and operate their application in a production environment. This is where containerization, CI/CD, and Infrastructure as Code come into play.
Containerization with Docker
Docker allows you to package an application and its dependencies into a standardized unit called a container. This solves the classic "it works on my machine" problem by ensuring that the application runs in a consistent environment, from development to staging to production.
Dockerfile: A text file that contains instructions for building a Docker image. It specifies the base image (e.g.,python:3.11-slim), copies the application code, installs dependencies, and defines the command to run the application.docker-compose.yaml: A file for defining and running multi-container Docker applications. For example, it can define both the application service and a database service, and manage the network between them.
CI/CD Fundamentals
Continuous Integration (CI) and Continuous Delivery/Deployment (CD) are cornerstone practices of DevOps. A CI/CD pipeline is an automated workflow that takes code from a commit and moves it through the stages of building, testing, and deployment.
Continuous Integration (CI): Developers frequently merge their code changes into a central repository. Each merge triggers an automated build and test run. This practice allows teams to detect integration issues early.
Continuous Delivery (CD): An extension of CI where code changes that pass all tests are automatically released to a staging or production environment. Continuous Deployment goes one step further by automatically deploying every passed change to production without manual intervention.
Automating this pipeline accelerates delivery, improves software quality by catching bugs earlier, and reduces the risk associated with manual deployments.
Infrastructure as Code (IaC)
Infrastructure as Code is the practice of managing and provisioning computing infrastructure (e.g., servers, databases, networks) through machine-readable definition files, rather than physical hardware configuration or interactive configuration tools. Tools like Terraform or AWS CloudFormation allow you to define your infrastructure in code, which can be version-controlled, reviewed, and automated. This brings the same benefits of software development—automation, consistency, and reproducibility—to infrastructure management, reducing manual errors and configuration drift.
Part 4: End-to-End Project – Building a Production-Grade Asynchronous Web Scraping API
This capstone project serves as a practical synthesis of the concepts discussed throughout this playbook. We will build a complete application from the ground up, applying principles of modern project setup, asynchronous programming, API development, containerization, and automated testing. This end-to-end process demonstrates not just how to use individual technologies, but how to weave them together into a cohesive, production-ready system.
4.1 System Design & Architecture
Before writing a single line of code, a proficient engineer designs the system.
Functional Requirements:
Scrape quotes from the website
http://quotes.toscrape.com
.
Extract the quote text, author, and associated tags for each quote.
The scraper must handle pagination to collect quotes from all available pages.
Expose the scraped data via a REST API.
The API should provide endpoints to retrieve all quotes and filter quotes by author.
Non-Functional Requirements:
High Throughput: The scraping process should be fast and efficient, capable of fetching multiple pages concurrently.
Low Latency: The API responses should be fast.
Scalability: The system should be designed to handle an increase in scraping tasks or API traffic.
Maintainability: The codebase should be well-structured, tested, and easy to understand.
Deployability: The application must be easily deployable in a consistent manner.
Architecture: We will design a simple system with two logical components that could be deployed as separate microservices in a larger application: a Scraper Worker and an API Server. For this project, we will implement them within a single
FastAPIapplication for simplicity, but the code will be structured to keep these concerns separate.Scraper Worker: An asynchronous component responsible for fetching and parsing web pages.
API Server: A
FastAPIapplication that serves the scraped data.Data Store: For this project, we will use an in-memory store (a simple Python list of dictionaries) to hold the scraped data. In a true production system, this would be replaced by a persistent database like PostgreSQL or MongoDB.
4.2 Step-by-Step Implementation
Step 1: Project Setup
First, we establish a professional project structure using the src layout and configure it with pyproject.toml.
Create the directory structure:
web-scraper-api/
├── src/
│ └── scraper_api/
│ ├── __init__.py
│ ├── main.py
│ ├── scraper.py
│ └── models.py
├── tests/
│ ├── __init__.py
│ └── test_api.py
├──.gitignore
└── pyproject.toml
Define
pyproject.toml: This file will manage our dependencies and tool configurations.Ini, TOML
[build-system]
requires = ["setuptools>=61.0"]
build-backend = "setuptools.build_meta"
[project]
name = "scraper-api"
version = "0.1.0"
dependencies = [
"fastapi>=0.110.0",
"uvicorn[standard]>=0.29.0",
"httpx>=0.27.0",
"beautifulsoup4>=4.12.3",
"pandas>=2.2.0"
]
[project.optional-dependencies]
dev = [
"pytest>=8.0.0",
"ruff>=0.3.0",
"black>=24.0.0"
]
[project.scripts]
scraper-api = "scraper_api.main:start"
[tool.setuptools.packages.find]
where = ["src"]
[tool.ruff]
line-length = 88
select =
[tool.black]
line-length = 88
Set up the virtual environment:
Bash
python -m venv.venv
source.venv/bin/activate
pip install -e.[dev]
Step 2: Asynchronous Data Ingestion
We'll use httpx and asyncio for efficient, concurrent web scraping.
BeautifulSoup will be used for parsing the HTML.
In src/scraper_api/scraper.py:
Python
import asyncio
import httpx
from bs4 import BeautifulSoup
from urllib.parse import urljoin
BASE_URL = "http://quotes.toscrape.com"
async def fetch_page(client: httpx.AsyncClient, url: str):
"""Fetches the content of a single page."""
try:
response = await client.get(url, timeout=10.0)
response.raise_for_status()
return response.text
except httpx.RequestError as e:
print(f"An error occurred while requesting {e.request.url!r}.")
return None
def parse_quotes(html_content: str):
"""Parses quotes from HTML content."""
soup = BeautifulSoup(html_content, 'html.parser')
quotes =
for quote in soup.select('div.quote'):
text = quote.select_one('span.text').get_text(strip=True)
author = quote.select_one('small.author').get_text(strip=True)
tags =
quotes.append({"text": text, "author": author, "tags": tags})
return quotes
def find_next_page(html_content: str):
"""Finds the URL of the next page, if it exists."""
soup = BeautifulSoup(html_content, 'html.parser')
next_li = soup.select_one('li.next > a')
if next_li and next_li.has_attr('href'):
return urljoin(BASE_URL, next_li['href'])
return None
async def scrape_all_quotes():
"""Scrapes all quotes from the website by handling pagination."""
all_quotes =
current_url = BASE_URL
async with httpx.AsyncClient() as client:
while current_url:
print(f"Scraping {current_url}...")
html = await fetch_page(client, current_url)
if html:
all_quotes.extend(parse_quotes(html))
current_url = find_next_page(html)
else:
break
return all_quotes
This module defines functions to fetch a page, parse quotes from it, find the next page link, and orchestrate the entire scraping process asynchronously.
Step 3: API Development & Data Validation
We will use FastAPI for its high performance and Pydantic for robust data validation.
Define Pydantic Models in
src/scraper_api/models.py: These models define the data structure for our API, ensuring type safety and providing automatic documentation.Python
from pydantic import BaseModel
from typing import List
class Quote(BaseModel):
text: str
author: str
tags: List[str]
Create the FastAPI Application in
src/scraper_api/main.py: This will be the entry point for our API server.Python
import uvicorn
from fastapi import FastAPI, HTTPException
from typing import List
import pandas as pd
from.models import Quote
from.scraper import scrape_all_quotes
app = FastAPI(
title="Quotes API",
description="An API to serve quotes scraped from quotes.toscrape.com",
version="1.0.0"
)
# In-memory data store
quotes_data: List[Quote] =
@app.on_event("startup")
async def load_data():
"""Load data on application startup by running the scraper."""
global quotes_data
scraped_quotes = await scrape_all_quotes()
quotes_data = [Quote(**q) for q in scraped_quotes]
print(f"Successfully loaded {len(quotes_data)} quotes.")
@app.get("/quotes", response_model=List[Quote])
async def get_all_quotes():
"""Retrieve all scraped quotes."""
return quotes_data
@app.get("/quotes/author/{author_name}", response_model=List[Quote])
async def get_quotes_by_author(author_name: str):
"""Retrieve quotes by a specific author."""
results = [quote for quote in quotes_data if quote.author.lower() == author_name.lower()]
if not results:
raise HTTPException(status_code=404, detail="Author not found")
return results
@app.get("/quotes/export/csv")
async def export_quotes_to_csv():
"""Export all quotes to a CSV file format as a string."""
if not quotes_data:
return {"message": "No data to export."}
df = pd.DataFrame([quote.model_dump() for quote in quotes_data])
return df.to_csv(index=False)
def start():
"""Launches the Uvicorn server."""
uvicorn.run("scraper_api.main:app", host="0.0.0.0", port=8000, reload=True)
This setup includes a startup event to run the scraper, endpoints for data retrieval, and leverages our
Pydanticmodel for response validation.
Step 4: Data Processing & Storage
In our main.py, we've already included an endpoint /quotes/export/csv that demonstrates how to process the scraped data (a list of dictionaries/Pydantic models) using pandas. It converts the list of Quote objects into a pandas DataFrame and then exports it to a CSV formatted string. This showcases a common data processing workflow in Python.
Step 5: Containerizing the Service
We'll create a Dockerfile to package our application into a container, making it portable and easy to deploy.
In the project root, create Dockerfile:
Dockerfile
# Use an official Python runtime as a parent image
FROM python:3.11-slim
# Set the working directory in the container
WORKDIR /app
# Set environment variables
ENV PYTHONDONTWRITEBYTECODE 1
ENV PYTHONUNBUFFERED 1
# Install system dependencies if needed
# RUN apt-get update && apt-get install -y...
# Install Poetry (or just use pip with pyproject.toml)
RUN pip install --upgrade pip
# Copy the project files into the container
COPY pyproject.toml pyproject.toml
COPY src/ /app/src/
# Install dependencies
RUN pip install.
# Expose the port the app runs on
EXPOSE 8000
# Command to run the application
CMD ["scraper-api"]
This Dockerfile creates a lean, reproducible environment for our application.
Step 6: Testing the Full Stack
Robust testing is crucial. We'll use pytest to write both unit tests for our scraping logic and integration tests for our API endpoints.
In tests/test_api.py:
Python
from fastapi.testclient import TestClient
from scraper_api.main import app
client = TestClient(app)
# A simple test to ensure the API starts and the root endpoint is available.
# In a real project, we would mock the scraper call for tests.
def test_read_main_endpoint():
# This test will trigger the startup event and run the scraper.
# For CI, you might want to mock `scrape_all_quotes` to avoid network calls.
response = client.get("/quotes")
assert response.status_code == 200
# The actual number of quotes can vary, but it should be a list.
assert isinstance(response.json(), list)
assert len(response.json()) > 0
def test_get_quotes_by_known_author():
# Assuming Albert Einstein is a known author from the scraped data
response = client.get("/quotes/author/Albert Einstein")
assert response.status_code == 200
data = response.json()
assert isinstance(data, list)
assert len(data) > 0
for quote in data:
assert quote['author'] == 'Albert Einstein'
def test_get_quotes_by_unknown_author():
response = client.get("/quotes/author/Unknown Author")
assert response.status_code == 404
assert response.json() == {"detail": "Author not found"}
These tests use pytest and FastAPI's TestClient to validate our API's behavior without needing a running server.
Step 7: Automating with CI/CD
Finally, we'll create a simple GitHub Actions workflow to automate our quality checks.
Create .github/workflows/ci.yml:
YAML
name: Python CI
on: [push, pull_request]
jobs:
build-and-test:
runs-on: ubuntu-latest
strategy:
matrix:
python-version: ["3.11"]
steps:
- uses: actions/checkout@v3
- name: Set up Python ${{ matrix.python-version }}
uses: actions/setup-python@v4
with:
python-version: ${{ matrix.python-version }}
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -e.[dev]
- name: Lint with Ruff
run: |
ruff check.
ruff format --check.
- name: Test with pytest
run: |
pytest
This workflow ensures that every push to the repository automatically triggers linting, formatting checks, and runs the entire test suite, providing rapid feedback and maintaining code quality.
Conclusion: The Continual Journey of a Proficient Python Developer
Achieving "strong proficiency" in Python is not a final destination but a continuous journey of learning, practice, and adaptation. This playbook has laid out a comprehensive roadmap, guiding the developer from foundational language mastery to the complex art of building and deploying production-grade systems. The journey is built on four essential pillars: Pythonic Mastery, which emphasizes writing clean, idiomatic, and efficient code; Performance & Scale Concepts, which provides the theoretical understanding of concurrency and algorithms needed to build scalable applications; The Professional's Toolkit, which covers the ecosystem of tools and practices for version control, testing, and deployment; and End-to-End Synthesis, which integrates these skills into a practical, real-world project.
As the software engineering landscape evolves, the role of the Python developer is also transforming. The rise of Artificial Intelligence and Machine Learning is a particularly potent force. AI is increasingly automating rote tasks such as boilerplate code generation, debugging, and even test creation, allowing developers to offload repetitive work and focus on higher-level challenges. The proficient engineer of the future will not be one who competes with AI, but one who leverages it as a powerful collaborator. This shifts the developer's focus from pure coding to more strategic activities like system architecture, complex problem-solving, and effective prompt engineering to guide AI tools. The demand for engineers who can design, oversee, and integrate these complex systems will only grow.
Simultaneously, architectural trends like distributed systems, serverless computing, and edge computing are reshaping how applications are deployed and operated. These paradigms offer new levels of scalability and efficiency, creating fresh opportunities for Python developers who are prepared to adapt and learn new deployment models. The skills outlined in this guide—particularly in concurrency, API design, and containerization—are directly applicable and essential for thriving in this new era.
The journey of a software engineer is one of lifelong learning. The technologies will inevitably change, but the fundamental principles of sound engineering—clarity, maintainability, scalability, and robustness—are timeless. To continue this journey, developers are encouraged to delve deeper into the foundational texts of the field. Books like Luciano Ramalho's Fluent Python , Martin Kleppmann's
Designing Data-Intensive Applications , and Andrew Hunt and David Thomas's
The Pragmatic Programmer offer invaluable wisdom that transcends any single technology and will serve as trusted companions on the path to true software craftsmanship.