
How to Build Production-Ready NER Systems: A Complete Guide for 2025
NER Systems That Scale — Build Like a Pro #ProductionNERGuide

In this episode, we dive deep into the world of Named Entity Recognition (NER)—an essential technology that powers everything from search engines to financial analytics. You'll learn:
What NER is and how it transforms unstructured text into structured entities
Why a data-centric approach is crucial for high-accuracy models
Annotation best practices using Human-in-the-Loop (HITL) and active learning
How to fine-tune transformer models, generative LLMs, and spaCy pipelines
Deployment tips, MLOps monitoring, and strategies for continuous improvement
Real-world applications and what the future holds for NER in NLP
Whether you're scaling NLP for healthcare, legal tech, or e-commerce, this guide will help you build robust and scalable systems. Subscribe now for more AI deep dives!
The Developer's Handbook to Production-Grade NER: An End-to-End Guide to Fine-Tuning and Deployment
Part I: Foundations of Custom Named Entity Recognition
Chapter 1: Beyond the Basics of NER
Named Entity Recognition (NER) serves as a cornerstone of modern Natural Language Processing (NLP), acting as a fundamental technique for information extraction. Its primary function is to identify and classify named entities within unstructured text into predefined categories, such as the names of persons, organizations, locations, dates, monetary values, and more. This process transforms raw, unstructured text into structured, machine-readable data, paving the way for deeper linguistic understanding and a wide array of downstream applications. While introductory examples often showcase the extraction of common entities, the true power and complexity of NER emerge when it is tailored for specialized, production-level systems.
1.1 The Core NER Process Deconstructed
At a high level, the journey from a raw text string to a set of structured, labeled entities follows a well-defined pipeline. Understanding these stages is essential for diagnosing issues and optimizing performance in a production environment. The process is not strictly linear but often iterative, with insights from later stages informing improvements in earlier ones.
The typical NER workflow includes the following steps :
Text Input: The process begins with the raw, unstructured text that requires analysis. For example: "Apple Inc. is planning to open a new office in San Francisco in March 2025.".
Text Preprocessing: This stage prepares the text for analysis. It involves several sub-tasks:
Tokenization: The text is segmented into individual units, or tokens, which can be words, punctuation, or other symbols. The example sentence would be tokenized into: ``.
Part-of-Speech (POS) Tagging: Each token is assigned a grammatical tag (e.g., noun, verb, adjective) to help the model understand its role in the sentence. For instance, "Apple" would be tagged as a proper noun (
NNP).
Feature Extraction: The model derives relevant features from the tokens to aid in classification. These can include contextual features (analyzing surrounding words), orthographic features (capitalization, punctuation), and lexical features (matching against dictionaries or gazetteers).
Model Application: A trained NER model is applied to the preprocessed text. This model could be a statistical model like a Conditional Random Field (CRF), a neural network, or a rule-based system designed to classify each token.
Entity Classification: The model assigns a predefined category label to tokens or sequences of tokens that it identifies as entities. In our example, the model would produce: ``.
Post-Processing: The initial output is refined to improve accuracy. This step can resolve ambiguities (e.g., determining if "Jordan" refers to a person or a country based on context), handle nested entities (an entity within another, like a person's name within an organization), and ensure overall consistency.
Structured Output Generation: The final, annotated text is produced in a structured format like JSON or XML, making it ready for use by other systems or for storage in a database.
1.2 The Crucial Leap to Domain-Specific NER
While off-the-shelf NER models, often trained on broad news corpora like CoNLL-2003 or OntoNotes, are excellent for general-purpose tasks, their utility diminishes sharply when applied to specialized domains. A model trained to recognize "Person," "Organization," and "Location" in news articles will likely fail to identify domain-specific entities such as "subdural hematoma" in a medical record, "mezzanine financing" in a financial document, or "Law reference" and "Jurisdiction" in a legal contract.
This performance gap is the primary motivation for fine-tuning. The business value of NER is often unlocked by its ability to extract these custom, high-value entities that are specific to an industry or problem space. For instance, in the renewable energy sector, a fine-tuned model can detect new technologies and startup names from news articles, providing critical business intelligence. Similarly, in fantasy literature, a domain rich with unique vocabulary, conventional models struggle, whereas fine-tuned models can successfully identify custom entities like character names and fictional locations. Therefore, mastering the process of fine-tuning is not just an academic exercise; it is a critical skill for building NER systems that deliver tangible value in real-world applications.
1.3 The Spectrum of NER Models
The field of NER offers a spectrum of modeling approaches, each with distinct strengths, weaknesses, and ideal use cases. A production-focused developer should be familiar with the entire range to select the appropriate tool for a given task. This guide will provide in-depth, practical instructions for the most relevant modern approaches.
Rule-Based and Hybrid Systems: These systems rely on handcrafted rules, such as regular expressions and dictionaries (gazetteers), to identify entities. A simple rule might state that any capitalized word following "Mr." is a person's name. While they can be quick to deploy and are highly interpretable, they are often brittle, difficult to maintain, and do not generalize well to unseen patterns. Hybrid systems augment machine learning models with rules to improve precision in specific, well-defined cases, offering a balance of adaptability and control.
Statistical Models (e.g., CRF): Before the deep learning era, statistical models like Conditional Random Fields (CRFs) were the state of the art. They treat NER as a sequence labeling problem and learn contextual patterns from annotated data. CRFs are often used as a final layer on top of neural networks (like BiLSTM-CRF) to enforce sequence-level constraints on predictions, improving the coherence of the output entity tags.
Transformer-Based Models (e.g., BERT): The advent of Transformer architectures, particularly models like BERT (Bidirectional Encoder Representations from Transformers), revolutionized NLP. These models are pre-trained on vast amounts of text, allowing them to learn deep, contextualized representations of language. By fine-tuning a pre-trained Transformer on a smaller, task-specific labeled dataset, developers can achieve state-of-the-art performance on custom NER tasks with significantly less data than training from scratch.
Generative Large Language Models (LLMs) (e.g., GPT): The most recent paradigm shift involves using large generative models like GPT for NER. These models can perform NER with minimal or no task-specific training through a technique called in-context learning, where the task is described in a detailed prompt with a few examples. They can also be fine-tuned on custom datasets to improve their reliability and adherence to specific output formats, offering a powerful but potentially costly alternative to smaller, specialized models.
Chapter 2: The Anatomy of a Production NER System
The transition from a proof-of-concept NER model developed in a Jupyter Notebook to a robust, scalable, and maintainable production service is a significant engineering challenge. While an academic project might consist of a single script and a static CSV file, a production system is a complex ecosystem of interconnected services designed for reliability, scalability, and continuous improvement.
2.1 From Jupyter Notebook to Production Service
A common pitfall for developers is underestimating the engineering effort required to operationalize an ML model. A model artifact, such as a saved .pkl or PyTorch file, is only one small component of the final product. A production NER system is a living application that must handle real-world data, serve predictions with low latency, and, most importantly, be designed to evolve and improve over time.
The fundamental distinction lies in the data flow. A prototype typically follows a linear, one-way path: data is used to train a model, which then makes predictions. A production system, however, is built around a continuous feedback loop. Data is used to train a model, the model makes predictions in a live environment, and the interactions with those predictions (e.g., user corrections, downstream application behavior) are logged and fed back into the system to create new training data for future model versions. This cyclical, self-improving nature is the hallmark of a mature MLOps practice.
This architectural mindset shift is critical. The design of every component, from the data annotation interface to the deployment infrastructure, must support this feedback loop. For example, the choice of an annotation tool is not merely about the initial labeling effort but also about its ability to facilitate fast, corrective labeling based on errors identified in production. Similarly, the inference service must not only return predictions but also log the inputs, outputs, and any available ground truth or user feedback to fuel the next iteration of the model.
2.2 Key Architectural Components
A production-grade NER system is composed of several key architectural components that work in concert. While the specific implementation will vary, these functional blocks are almost always present.
Data Ingestion & Preprocessing Pipeline: This is the entry point for all data into the system. It is responsible for collecting raw, unstructured data from various sources—such as document stores, databases, web scraping, or real-time event streams—and preparing it for the next stage. This may involve converting file formats (e.g., PDF to text), cleaning raw text, and segmenting large documents into manageable chunks for annotation.
Annotation & Data Management: This is the heart of a custom NER system, where the "source of truth" for the model is created and maintained. It consists of an annotation interface (which could be a commercial tool like Labelbox, an open-source one like Doccano, or a custom-built application) and a database for storing and versioning the labeled data. This component must support collaborative workflows and robust quality control measures.
Training & Experimentation Service: This is the environment where models are built. It typically involves cloud-based infrastructure with access to GPUs or other accelerators to handle the computational demands of training deep learning models. This service is integrated with an experiment tracking tool, such as Weights & Biases (W&B) or MLflow, to log hyperparameters, metrics, and model artifacts for every training run, ensuring reproducibility and facilitating model comparison.
Inference Service: Once a model is trained and validated, it is deployed as an inference service. This is typically a scalable, low-latency API that exposes the model's prediction capabilities to other applications or end-users. Modern implementations often use lightweight web frameworks like FastAPI, containerize the service with Docker for portability, and deploy it on cloud platforms or on-premise servers.
Monitoring & Feedback Loop: This component closes the loop of the production lifecycle. It continuously tracks the performance of the deployed model in the live environment. This includes monitoring operational metrics (e.g., latency, error rate) and, crucially, model quality metrics (e.g., data drift, prediction drift, and accuracy against new ground truth). It captures data that can be used for retraining, including model predictions, user feedback, and newly available labeled data, channeling it back to the annotation and training services to create a virtuous cycle of improvement.
Part II: The NER Project Lifecycle: From Concept to Production
Building a successful NER product requires more than just technical expertise; it demands engineering discipline. Applying a formal project management lifecycle provides the structure necessary to navigate the complexities of ML development, manage risks, and deliver value on time and within budget. The lifecycle consists of five distinct phases: initiation, planning, execution, monitoring and control, and closure.
Chapter 3: Initiating and Planning Your NER Project
The early phases of an ML project are the most critical. Decisions made during initiation and planning have an outsized impact on the project's ultimate success. For data-centric projects like NER, failure often stems from inadequate planning and data strategy, not from the choice of model architecture. A rigorous project management framework is therefore not a bureaucratic hurdle but a vital risk mitigation tool.
3.1 The Initiation Phase: Justification and Feasibility
Before any code is written, the project's existence must be justified. This phase is about answering two fundamental questions: "Should we do this project?" and "Can we do this project?". The process involves several key activities:
Business Case: Articulating the problem the NER system will solve and the value it will create. For example, "By automatically extracting key clauses from legal contracts, we will reduce manual review time by 75%, saving X dollars per year."
Feasibility Study: Assessing the technical and operational viability of the project. For NER, this includes evaluating the availability and quality of source documents, the feasibility of acquiring or creating labeled data, the availability of domain experts for annotation, and the required computational resources.
Cost-Benefit Analysis: Estimating the costs (e.g., annotator salaries, cloud computing bills, developer time) versus the expected benefits (e.g., cost savings, revenue generation, efficiency gains).
3.2 The Project Charter: Your North Star
Once the project is deemed feasible and justified, its core parameters are formalized in a project charter. This document serves as the project's foundational agreement and reference point. It typically includes:
Project Objectives: A clear, high-level statement of what the project aims to achieve.
Key Stakeholders: Identifying everyone with an interest in the project, including the project sponsor, ML engineers, data annotators, domain experts, product managers, and the end-users of the system.
High-Level Scope and Deliverables: Defining the boundaries of the project and the major outputs (e.g., a deployed API, a labeled dataset).
Success Criteria: Establishing the top-level metrics for success, which should be tied to business outcomes.
3.3 The Planning Phase: Building the Roadmap
The planning phase is where the high-level vision from the charter is translated into a detailed, actionable roadmap. This is arguably the most intensive phase for an ML project manager, as it involves creating a series of interconnected plans that will guide the entire development process. These plans should be stored in a centralized, accessible location, such as a project management tool like Jira or a knowledge base like Confluence.
Project Plan & Work Breakdown Structure (WBS): The project is decomposed into smaller, manageable tasks and organized into a logical sequence. A typical WBS for an NER project would include phases like Data Collection, Schema Definition, Annotation Guideline Creation, Data Annotation (Pilot), Data Annotation (Full), Model Training (V1), Model Evaluation, Deployment, and Monitoring Setup. A Gantt chart is an excellent tool for visualizing these tasks, their durations, and their dependencies.
Risk Plan & Risk Register: This is where the project team proactively identifies potential problems and plans for them. The technical challenges inherent in NER should be framed as project risks. For example:
Risk: Inconsistent annotation due to ambiguous entity definitions.
Mitigation: Develop a comprehensive annotation guide with clear examples and conduct regular calibration sessions with annotators to ensure alignment.
Risk: Model performance (e.g., F1-score) does not meet the minimum threshold required for business value.
Mitigation: Plan for multiple modeling experiments with different architectures and hyperparameter tuning; secure a budget for additional data annotation if needed.
Risk: Concept drift in production leads to performance degradation over time.
Mitigation: Design and budget for a production monitoring system and a periodic model retraining pipeline from the outset.
Financial Plan: A detailed budget is created, allocating funds for all anticipated expenses. For NER projects, the most significant costs are often human-centered—specifically, the cost of data annotation. Other major costs include cloud compute for GPU-intensive training and the ongoing cost of hosting the deployed model.
Resource Plan: The specific roles and responsibilities of the project team are defined. This includes identifying the ML engineers who will build the system, the data annotators (who may need to be domain experts), and the project manager who will oversee the process.
Communication Plan: This plan establishes the cadence and channels for communication among stakeholders. It defines regular status meetings, progress reporting formats (e.g., dashboards), and escalation pathways for issues, ensuring everyone remains informed and aligned.
Quality & Acceptance Plan: This plan defines what "good" looks like in concrete, measurable terms. It translates vague goals into SMART (Specific, Measurable, Attainable, Relevant, Timely) objectives. For an NER project, this moves beyond a simple technical metric like "achieve a high F1-score." A better objective would be: "Within Q3, deliver a deployed NER model for customer support tickets that identifies the 'PRODUCT_NAME' and 'ERROR_CODE' entities with a per-entity precision of at least 95%, in order to enable automated ticket routing and reduce average resolution time by 20%." This plan also defines the quality gates for each phase, such as a minimum Inter-Annotator Agreement score for the labeled dataset before training can begin.
Chapter 4: Execution and Closure
With a robust plan in place, the project moves into the active phases of building, monitoring, and delivering the NER system.
4.1 The Execution Phase: Bringing the Plan to Life
The execution phase is where the bulk of the technical development occurs, as detailed in Parts III, IV, and V of this handbook. It is the implementation of the project plan. During this phase, the project manager's role shifts to active oversight: assigning tasks, clearing roadblocks, managing resources, and facilitating communication to keep the project moving forward. Team collaboration is paramount, and tools like Jira for task management and visual boards (e.g., Kanban) for tracking progress are invaluable for maintaining alignment and momentum.
4.2 The Monitoring & Controlling Phase
This phase does not happen after execution; it runs concurrently with it. It is the process of continuously measuring project performance against the plan and taking corrective action when deviations occur. The project manager tracks key performance indicators (KPIs) related to schedule, budget, and scope. For instance, they monitor the annotation progress against the timeline, track cloud computing spend against the budget, and manage any requested changes to the entity schema through a formal change control process. This ensures that the project stays on course to meet its objectives.
4.3 The Closure Phase: Delivering and Learning
A project is not complete simply when a model is deployed. The closure phase formalizes the end of the project and ensures its value is sustained. Key activities in this phase include:
Deliverable Verification and Handover: Ensuring all deliverables defined in the project plan have been completed and formally handing over the operational system to the team responsible for its long-term maintenance.
Stakeholder Sign-off: Obtaining formal acceptance of the project outcome from the project sponsor and key stakeholders.
Post-Project Review and Lessons Learned: This is a crucial step for organizational learning. The team conducts a retrospective to discuss what went well, what went wrong, and what could be improved in future projects. These insights are documented and archived, creating a valuable knowledge base.
Celebrating Success: Acknowledging the team's contributions and celebrating the successful completion of the project is vital for morale and motivation.
By adhering to this structured lifecycle, a development team can transform the often chaotic and unpredictable process of building an ML system into a disciplined engineering endeavor, significantly increasing the likelihood of delivering a successful, high-value NER product.
Part III: The Data-Centric Approach: Engineering High-Quality Datasets
In the realm of custom NER, the adage "garbage in, garbage out" is an immutable law. The performance of any model, regardless of its architectural sophistication, is fundamentally capped by the quality of the data it is trained on. A data-centric approach, which prioritizes the systematic engineering of high-quality datasets, is therefore the most critical component of a successful NER project. This part delves into the three pillars of data engineering for NER: designing a robust entity schema, mastering the art of data annotation, and leveraging intelligent workflows like Human-in-the-Loop to maximize efficiency.
Chapter 5: Designing Your Entity Schema
The entity schema is the blueprint for your NER model; it defines the universe of categories the model will learn to recognize. A poorly designed schema—one that is ambiguous, overly complex, or misaligned with business goals—will doom a project from the start. The design process is not a purely technical task; it requires deep domain knowledge and a clear understanding of the problem space.
5.1 The Foundation of Your Model
The first step in schema design is to immerse oneself in the source data. By reviewing a representative sample of the documents that the model will process, developers and domain experts can identify the entities that hold the most business value. For example, when analyzing financial reports, entities like "Company Name," "Revenue," "Ticker Symbol," and "Filing Date" are likely candidates. This initial exploration forms the basis for the formal entity list.
5.2 Best Practices for Schema Design
A well-designed schema is clear, consistent, and learnable. Microsoft's documentation for Azure AI services provides an excellent set of best practices that are broadly applicable :
Avoid Ambiguity: Ambiguity arises when entity types are conceptually similar and difficult for a model to distinguish based on context alone. For instance, in a legal contract, trying to differentiate between "Name of First Party" and "Name of Second Party" is challenging because both are typically person or organization names. The model would require a vast number of examples to learn the subtle contextual cues. A more robust approach might be to define a single, unambiguous entity type, such as "PARTY," and use post-processing logic to determine its role in the contract. Avoiding ambiguity saves significant time and annotation effort and yields better results.
Avoid Overly Complex Entities: It is tempting to define entities that capture large, composite pieces of information, such as a single "Address" entity. However, addresses appear in countless variations, making it an extremely challenging pattern for a model to learn precisely. A much more effective strategy is to break the complex entity down into smaller, simpler components. For example, "Address" can be decomposed into "Street Name," "City," "State," and "Zip Code." The model can learn to recognize these simpler, more consistent patterns with far fewer labeled examples.
Create Clear Definitions: For every entity type in the schema, a precise, written definition must be created. This definition should eliminate any gray areas and provide clear instructions on what should and should not be included in the entity span. These definitions will become the cornerstone of the annotation guidelines, ensuring that all annotators apply the labels consistently.
Chapter 6: The Art and Science of Data Annotation
Data annotation is the process of manually labeling raw text to create the ground truth training data for the model. It is often the most time-consuming and expensive part of a custom NER project, and its quality directly determines the model's performance.
6.1 The "Garbage In, Garbage Out" Principle
The single most important factor for a successful NER model is a high-quality, consistently labeled dataset. Even the most advanced Transformer model cannot overcome the limitations of noisy, inconsistent, or incomplete training data. Investing time and resources in a meticulous annotation process will yield far greater returns than endlessly tweaking model hyperparameters.
6.2 Establishing Annotation Guidelines
To ensure consistency, especially when multiple people are involved in labeling, a comprehensive set of annotation guidelines is non-negotiable. This document should be a living guide that is updated as new edge cases are discovered. It should include:
The formal entity schema with the clear definitions created in the previous chapter.
Positive and negative examples for each entity type.
Clear instructions for handling common challenges, such as nested entities, ambiguous cases, and multi-token entities.
Rules for resolving common errors like inconsistent labeling (e.g., sometimes labeling "Inc." as part of an organization name, and sometimes not) and mislabeling due to context oversight.
6.3 Data Annotation Best Practices
The process of labeling should follow a set of strict principles to ensure the resulting dataset is clean and accurate. Key practices include :
Label Precisely: The annotated span of text should include only the characters that make up the entity, with no leading or trailing whitespace or punctuation that is not part of the entity itself.
Label Consistently: The same conceptual entity must be labeled with the same entity type across the entire dataset. This is where the annotation guidelines are critical.
Label Completely: Every single instance of every entity type must be labeled in all documents. Missing an entity in one document teaches the model that the same pattern is not an entity in that context, which can confuse the learning process. Features like auto-labeling in some tools can help ensure completeness.
6.4 Choosing Your Annotation Tool
Selecting the right tool for data annotation is a critical decision that depends on the project's scale, budget, team structure, and technical requirements. A wide range of tools is available, from open-source applications to enterprise-grade platforms.

6.5 Quality Control: Ensuring Annotator Agreement
When multiple annotators are working on a dataset, it is crucial to measure and maintain their consistency. The standard practice for this is to calculate the Inter-Annotator Agreement (IAA). This involves having two or more annotators independently label the same subset of documents. The resulting annotations are then compared, and any disagreements are discussed and resolved. This process, often called adjudication, not only corrects errors in the data but also helps refine the annotation guidelines by highlighting ambiguous cases. Regular reviews and feedback sessions are essential for maintaining high-quality output throughout the project.
Chapter 7: Human-in-the-Loop (HITL) and Active Learning
The high cost and time-intensive nature of manual data annotation represent the single biggest bottleneck in building custom NER models. Human-in-the-Loop (HITL) and Active Learning are powerful strategies designed to overcome this challenge by intelligently combining human expertise with machine intelligence to create high-quality datasets with maximum efficiency.
7.1 The Problem: The High Cost of Labeling
Creating a sufficiently large and high-quality labeled dataset for a custom NER task can require thousands of person-hours of manual work. For complex domains, this work must be done by expensive subject matter experts, further increasing the cost. HITL and Active Learning aim to reduce this burden by focusing human effort on the most valuable and impactful labeling tasks.
7.2 What is Human-in-the-Loop?
Human-in-the-Loop is a framework that embeds human intelligence directly into the machine learning workflow. Instead of a one-time handoff of labeled data from humans to the machine, HITL creates a continuous, collaborative feedback loop. In a typical HITL system for NER, the process works as follows :
An initial model is trained on a small set of labeled data.
The model processes new, unlabeled documents and suggests potential entity annotations.
A human annotator reviews these suggestions. They can quickly accept correct suggestions, reject incorrect ones, or manually label entities the model missed.
This human feedback is used to correct the annotations and is added to the training set.
The model is retrained on the enriched dataset, becoming more accurate.
The process repeats, with the model getting progressively better and requiring less human correction over time.
This approach is highly effective because it leverages the strengths of both humans and machines. The machine handles the bulk of the repetitive work, while the human applies nuanced judgment and contextual knowledge to handle ambiguity and correct errors.
7.3 Active Learning: Smart Data Selection
Active Learning is a specific strategy within the HITL framework that makes the data selection process more intelligent. Instead of presenting random unlabeled documents to the annotator, an active learning system uses the model itself to select the examples that it would benefit most from having labeled. The core idea is to focus human attention on the data points where the model is most uncertain. Common active learning strategies for NER include:
Uncertainty Sampling: The system prioritizes documents or text spans for which the model has the lowest confidence in its predictions. These are the examples the model is most likely to be mislabeling, and therefore, getting the correct label provides the most new information.
Query-by-Committee (QBC): This technique involves training an ensemble of several different models. The system then selects data points where the models in the committee disagree the most on the correct prediction. This disagreement is a strong signal of ambiguity or difficulty that requires human clarification.
Diversity-Based Sampling: To prevent the model from focusing too narrowly on one type of uncertainty, this strategy ensures that the data selected for labeling is diverse and representative of the overall data distribution. This can be achieved by clustering the data and sampling from different clusters, helping the model build a more robust and generalizable understanding.
7.4 A Modern, Accelerated Annotation Workflow
The convergence of LLMs, active learning, and traditional annotation tools has given rise to a highly efficient, state-of-the-art workflow for bootstrapping custom NER datasets. This hybrid approach can dramatically reduce the time and effort required to go from raw text to a high-quality training set.
The process begins not with a human, but with a powerful generative LLM like GPT-4. Using a carefully crafted prompt that includes the entity schema and a few examples (few-shot prompting), the LLM is used to perform an initial annotation pass on a large volume of unlabeled data. This step, sometimes called zero-shot or few-shot annotation, produces a large, "silver-standard" dataset that is reasonably accurate but may contain errors or inconsistencies.
Next, this LLM-generated dataset is loaded into a human-centric annotation tool that supports model-assisted labeling, such as Prodigy. A human domain expert then reviews the LLM's predictions in a rapid HITL workflow. Instead of labeling from scratch, the expert's task is reduced to quickly accepting correct labels and correcting the incorrect ones. This human validation and refinement step elevates the "silver-standard" dataset to a "gold-standard" one, suitable for training a production model.
Finally, this high-quality, human-verified dataset is used to fine-tune a smaller, more efficient, and specialized model, such as a BERT variant or a spaCy model. These models are often much faster and cheaper to run for high-volume inference in a production environment compared to large, general-purpose LLMs. This three-step process—
LLM-Bootstrapping, Human-in-the-Loop Refinement, and Specialized Model Fine-Tuning—represents one of the most effective strategies available today for building custom, production-grade NER systems.
7.5 The Role of Domain Experts
It is crucial to recognize that for complex or highly specialized domains, such as legal, financial, or biomedical text, the "human" in the loop should be a domain expert. An ML engineer may not have the necessary contextual knowledge to correctly annotate or validate entities like "mezzanine financing" or "acute myeloid leukemia." Involving domain experts in the annotation and quality control process is essential for building a model that is not only technically sound but also semantically correct and truly valuable to the business.
Part IV: The Art of Fine-Tuning: A Practical Guide to State-of-the-Art NER Models
With a high-quality dataset in hand, the next stage is to train a model that can learn the desired entity patterns. Fine-tuning pre-trained models has become the standard approach, as it leverages the vast linguistic knowledge already encoded in these models, allowing for high performance with relatively small custom datasets. This part provides practical, code-level guidance for fine-tuning three of the most important classes of NER models: Transformers (like BERT) via Hugging Face, generative LLMs (like GPT), and efficient production models with spaCy.
Chapter 8: Fine-Tuning Transformer Models with Hugging Face
Fine-tuning Transformer-based models from the Hugging Face ecosystem is often the go-to choice for achieving state-of-the-art performance on custom NER tasks. These models, pre-trained on massive text corpora, have developed a nuanced understanding of grammar, syntax, and semantics, which can be effectively transferred to a new, specific task.
8.1 The Power of Transfer Learning
Transfer learning is the machine learning technique of taking a model developed for one task and reusing it as the starting point for a model on a second task. For NER, this means starting with a general-purpose language model like BERT and adapting it to recognize a custom set of entities. This approach is incredibly powerful because it drastically reduces the amount of labeled data and computation time needed compared to training a model from scratch.
8.2 Setting Up the Environment
The Hugging Face ecosystem provides a suite of powerful, user-friendly libraries for this task. The essential packages can be installed via pip: !pip install transformers datasets seqeval accelerate torch
transformers: Provides the model architectures (e.g.,AutoModelForTokenClassification) and theTrainerAPI.datasets: A library for efficiently loading and processing large datasets.seqeval: The standard library for evaluating token classification tasks like NER.accelerate: Simplifies running training on different hardware setups, including multi-GPU and TPUs.torch: The deep learning framework on which the models run.
8.3 Data Loading and Preprocessing
The most technically challenging part of fine-tuning for NER is correctly preparing the data for the model. This involves tokenizing the text and ensuring the labels remain aligned with the new, potentially fragmented tokens. The Hugging Face token classification tutorial provides a robust workflow for this process.
Loading the Data: The
datasetslibrary can load data from the Hugging Face Hub or from local files (e.g., JSON, CSV). For this example, we assume a dataset format similar to CoNLL-2003, with columns fortokens(a list of words) andner_tags(a list of corresponding integer labels).Handling Subword Tokenization: Transformer models like BERT use subword tokenization (e.g., WordPiece or BPE), where an uncommon word might be split into multiple tokens (e.g., "boycott" -> "boy", "##cott"). This creates a mismatch between the original word-level labels and the new subword-level tokens. The
word_ids()method from a fast tokenizer can be used to map each subword token back to its original word index.Aligning Labels: A function must be written to align the labels with the subword tokens. The standard strategy is to assign the correct label to the first subword token of a word and a special "ignore" label (
-100in Hugging Face) to all subsequent subword tokens and special tokens (likeand). The-100label tells the model to ignore these tokens when calculating the loss function.
A Python function to perform this tokenization and alignment on a batch of examples would look like this:
Python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
def tokenize_and_align_labels(examples):
tokenized_inputs = tokenizer(examples["tokens"], truncation=True, is_split_into_words=True)
labels =
for i, label in enumerate(examples["ner_tags"]):
word_ids = tokenized_inputs.word_ids(batch_index=i)
previous_word_idx = None
label_ids =
for word_idx in word_ids:
if word_idx is None:
label_ids.append(-100)
elif word_idx!= previous_word_idx:
label_ids.append(label[word_idx])
else:
label_ids.append(-100)
previous_word_idx = word_idx
labels.append(label_ids)
tokenized_inputs["labels"] = labels
return tokenized_inputs
This function can then be applied to the entire dataset using dataset.map(tokenize_and_align_labels, batched=True).
8.4 The Fine-Tuning Process
Hugging Face's Trainer API provides a high-level, feature-rich abstraction for the training process, handling the training loop, evaluation, and logging automatically.
Configure Training Arguments: The
TrainingArgumentsclass is used to specify all the hyperparameters and settings for the training run. This includes the output directory, evaluation strategy, learning rate, number of epochs, and options for pushing the model to the Hugging Face Hub.Define Evaluation Metrics: A function must be created to compute the relevant metrics during evaluation. For NER, this involves using the
seqevallibrary to calculate entity-level precision, recall, and F1-score. The function will need to decode the model's predictions (logits) and the true labels, convert them from integers to their string representations, and filter out the-100ignore indices before passing them toseqeval.Instantiate the Trainer: The
Trainerobject brings everything together: the model, training arguments, datasets, a data collator (DataCollatorForTokenClassificationwhich handles padding), and the metrics computation function.
A typical fine-tuning script would include:
Python
from transformers import AutoModelForTokenClassification, TrainingArguments, Trainer, DataCollatorForTokenClassification
import evaluate
import numpy as np
# Assume tokenized_datasets, label_list are defined
model = AutoModelForTokenClassification.from_pretrained("bert-base-cased", num_labels=len(label_list))
metric = evaluate.load("seqeval")
def compute_metrics(p):
predictions, labels = p
predictions = np.argmax(predictions, axis=2)
#... (code to remove -100 and convert to string labels)...
results = metric.compute(predictions=true_predictions, references=true_labels)
return {"precision": results["overall_precision"], "recall": results["overall_recall"], "f1": results["overall_f1"]}
training_args = TrainingArguments(
output_dir="my-awesome-ner-model",
learning_rate=2e-5,
per_device_train_batch_size=16,
num_train_epochs=3,
weight_decay=0.01,
evaluation_strategy="epoch",
push_to_hub=True,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
tokenizer=tokenizer,
data_collator=DataCollatorForTokenClassification(tokenizer=tokenizer),
compute_metrics=compute_metrics,
)
trainer.train()
The choice of hyperparameters is critical for successful fine-tuning. While optimal values depend on the specific dataset and model, the following table provides empirically tested starting points.
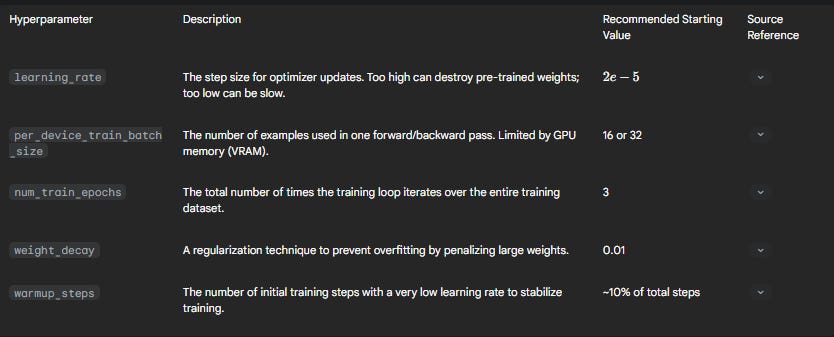
8.5 Advanced Techniques
For more challenging tasks or larger datasets, advanced techniques can improve stability and speed:
Gradient Clipping: Prevents the "exploding gradients" problem in deep networks by capping the magnitude of gradients during backpropagation. This can be enabled in a custom PyTorch loop with
torch.nn.utils.clip_grad_norm_.Mixed Precision Training: Uses a combination of 16-bit and 32-bit floating-point types to accelerate training and reduce memory usage on modern GPUs. This can be enabled in
TrainingArgumentswithfp16=True.
For developers who require maximum flexibility, forgoing the Trainer API and writing a custom training loop in native PyTorch is also a viable option. This provides granular control over every aspect of the training process, from data loading to gradient updates.
Chapter 9: Leveraging Generative LLMs (GPT) for NER
The emergence of powerful generative Large Language Models (LLMs) like OpenAI's GPT series has introduced a new paradigm for tackling NLP tasks, including NER. These models can perform NER "out of the box" with clever prompting and can be fine-tuned to achieve high levels of accuracy and reliability on custom tasks.
9.1 The New Paradigm: NER as a Generation Task
Unlike traditional NER models that perform token classification, generative LLMs treat NER as a text-to-text generation task. The model takes an input string (the text to be analyzed) and generates an output string that contains the extracted entities in a structured format. This approach is made possible by in-context learning, where the model is guided by a detailed prompt that describes the task and provides a few examples (few-shot learning).
9.2 Prompt Engineering for NER
The quality of an LLM's output is highly dependent on the quality of its prompt. Crafting an effective prompt is an empirical process of experimentation and refinement. Key components of a strong NER prompt include :
Task Description: A clear and unambiguous instruction telling the model what to do. For example: "Your task is to identify and label all Person and Location entities in the provided text."
Few-Shot Examples: Providing one or more examples of the desired input-output behavior. This is the most effective way to teach the model the exact output format it should produce.
Output Formatting Instructions: Explicitly defining the desired output structure. This can be a standard format like JSON or a custom format using special tags, such as
@@William Pitt##Person@@. Instructing the model to generate a JSON object with specific keys (entity_type,entity_value,start_position) is a common and effective strategy.Handling Edge Cases and Biases: Prompts can be used to correct undesirable model behaviors. For example, LLMs may have a tendency to label pronouns like "he" or "she" as Person entities. Adding a direct instruction like "DON’T LABEL PRONOUNS AS PERSON" near the end of the prompt can mitigate this issue. This leverages the model's "recency bias," where it pays more attention to the most recent parts of the prompt.
9.3 Fine-Tuning GPT Models
While few-shot prompting can be surprisingly effective, fine-tuning a generative model on a custom dataset of examples can lead to significant improvements in performance, consistency, and cost-effectiveness (by allowing the use of a smaller, fine-tuned model). The OpenAI fine-tuning API provides a streamlined process for this.
The workflow involves:
Preparing Data: The training data must be formatted into a JSON Lines (
.jsonl) file. Each line is a JSON object representing a single training example. For conversational models, each example contains a "messages" list with a sequence of "system," "user," and "assistant" roles. The "user" message contains the input text within the prompt, and the "assistant" message contains the desired "ground truth" output that the model should learn to replicate.Uploading Data: The
.jsonlfile is uploaded to OpenAI's servers using their API.Starting a Fine-Tuning Job: A fine-tuning job is initiated via an API call, specifying the uploaded training file and the base model to be fine-tuned (e.g.,
gpt-4o-mini-2024-07-18). OpenAI automatically handles the selection of hyperparameters like learning rate and batch size based on the dataset size.Using the Fine-Tuned Model: Once the job is complete, a new model ID is generated. This ID can be used in subsequent API calls to get predictions from the specialized, fine-tuned model.
Studies show that fine-tuning can substantially boost performance. For example, one analysis found that a fine-tuned GPT-4o-mini improved its F1-score on a custom NER task from 0.71 to 0.85, while also improving precision and reducing the model's tendency to over-predict entities.
9.4 Open-Source Alternatives
While OpenAI's models are powerful, they are proprietary and can be costly for high-volume applications. An increasingly popular alternative is to fine-tune open-source LLMs like EleutherAI's GPT-J or Meta's Llama series. This approach offers several advantages:
Cost-Effectiveness: Running inference on a self-hosted open-source model can be significantly cheaper than paying for API calls.
Data Privacy and Security: The data and the model remain within the organization's own infrastructure, which is a critical requirement for industries like healthcare and finance.
Customization and Control: Developers have full control over the model architecture, training process, and deployment environment.
The process of fine-tuning these models is conceptually similar to the Hugging Face workflow, leveraging the same libraries and principles to adapt a pre-trained generative model to a specific NER task.
Chapter 10: Building Custom Models with spaCy
While large Transformer models and LLMs often dominate the headlines, the spaCy library remains an outstanding choice for building production-grade NLP components. It is designed from the ground up for speed, efficiency, and reliability, making it an ideal tool when NER is one component of a larger, performance-critical application.
10.1 Why spaCy? Speed, Efficiency, and Production-Readiness
SpaCy's key advantages lie in its production-oriented design:
Performance: SpaCy's models are highly optimized for CPU execution, delivering inference speeds that are often an order of magnitude faster than large Transformer models.
Efficiency: It has a smaller memory footprint and fewer dependencies, making it easier to package and deploy.
Robustness: SpaCy provides a stable, well-documented API and a clear, reproducible training workflow, which are essential for building maintainable production systems.
10.2 Training with spaCy v3
The modern spaCy v3 training workflow is configuration-driven, which promotes reproducibility and makes it easy to track experiments. The end-to-end process is straightforward :
Prepare Data in
DocBinFormat: The training data, which is typically a list of(text, {"entities": [(start, end, label)]})tuples, must be converted into spaCy's efficient binary.spacyformat. This is done using theDocBinclass, which serializes a collection ofDocobjects to disk. A script iterates through the training data, creates aDocobject for each text, adds the entity spans, and then adds theDocto aDocBininstance before saving it.Create and Customize the Config File: All training settings, including model architecture, hyperparameters, and data paths, are controlled by a single configuration file,
config.cfg. SpaCy provides a user-friendly web widget or a command-line utility (spacy init fill-config) to automatically generate a base configuration file. This base file is then customized by pointing thetrainanddevvariables to the paths of the newly created.spacytraining and validation files.Train from the Command Line: With the data and config file prepared, training is initiated with a single command:
python -m spacy train config.cfg --output./output_model. SpaCy handles the entire training and evaluation process, saving the best-performing model to the specified output directory.
10.3 The Challenge of Catastrophic Forgetting
A critical phenomenon to be aware of when fine-tuning pre-trained spaCy models is catastrophic forgetting. When a model like
en_core_web_lg, which is pre-trained to recognize general entities like PERSON, ORG, and LOC, is fine-tuned only on a new set of custom entities (e.g., PROGRAMMING_LANGUAGE, FRAMEWORK_LIBRARY), the optimization process will adjust the model's weights exclusively for the new task. This often results in the model completely "forgetting" its ability to recognize the original, general-purpose entities. The new model will be good at the custom task, but its general capabilities will be lost.
10.4 The Solution: Up-training and Data Blending
The solution to catastrophic forgetting is not to abandon fine-tuning, but to approach it more thoughtfully through a process sometimes called up-training. Instead of training only on new data, the model should be updated with a blended dataset that includes examples of both the new custom entities and the original entities that need to be preserved.
For example, if the goal is to add the SKILL entity to a model that already knows PERSON, the training data should contain examples like:
"John Doe is an expert in Python programming."Entities: ``
By providing examples that mix old and new knowledge, the model learns to integrate the new entity type without overwriting the weights responsible for the old ones. This ensures that the updated model is an extension of the original, rather than a complete replacement, preserving its valuable pre-trained capabilities.
Chapter 11: A Comparative Analysis: Choosing the Right Model for Your Task
There is no single "best" NER model for every situation. The optimal choice is a function of the specific project requirements, including accuracy needs, budget constraints, data availability, latency requirements, and the development team's expertise. This chapter provides a framework for comparing the three major approaches—fine-tuned Transformers, generative LLMs, and custom spaCy models—to help developers make an informed decision.
11.1 There is No "Best" Model
Comparative studies consistently show that different models excel in different contexts. For instance, on domain-specific tasks with unique vocabularies like fantasy literature, off-the-shelf models like Flair, Trankit, and spaCy have been shown to outperform others without modification. In contrast, for extracting skills from Russian job vacancies, a fine-tuned RuBERT model outperformed LLMs across most metrics. When comparing spaCy to LLMs like GPT and Bard on general text, the LLMs demonstrate a superior ability to understand broader context and provide richer output, while spaCy is more limited but faster. The key takeaway is that the choice of model must be driven by a careful analysis of the project's specific trade-offs.
11.2 Performance vs. Cost vs. Complexity
The decision framework can be broken down into three main axes:
Fine-tuned Transformers (e.g., BERT): This approach often represents the sweet spot for custom NER tasks. It typically achieves the highest performance when a sufficient amount of high-quality labeled data (at least a few hundred to a few thousand examples) is available. The primary costs are associated with the data annotation effort and the GPU computation required for fine-tuning. The complexity is moderate, well-supported by libraries like Hugging Face.
Generative LLMs (e.g., GPT-4): These models are the champions of few-shot and zero-shot learning. They can achieve remarkable performance with very little or no labeled data, making them an excellent choice for rapid prototyping or when data annotation is prohibitively expensive. However, their inference costs are typically much higher per-request, which can be a major issue for high-volume applications. Fine-tuning an LLM can improve its consistency and potentially allow for the use of a smaller, cheaper model, but the process itself can be expensive.
Custom spaCy Models: SpaCy's primary strengths are speed and efficiency. For applications where low latency and low computational cost are critical, a custom spaCy model is often the best choice. While its raw accuracy on highly complex, nuanced tasks might not always match that of the largest Transformer models, its performance is highly competitive and its production-readiness is unparalleled. The training process is fast and resource-efficient, often running effectively on a CPU.
The following table summarizes these trade-offs to guide the selection process.

Part V: Operationalizing NER: Deployment, Monitoring, and Maintenance
A trained model artifact is not a product. The process of operationalizing a model—deploying it into a production environment, monitoring its performance, and maintaining it over time—is what transforms a data science experiment into a reliable business solution. This is the domain of MLOps (Machine Learning Operations), and it is essential for realizing the long-term value of any NER system.
Chapter 12: Advanced Evaluation for Production
Before deploying a model, it must be rigorously evaluated. Standard metrics like an overall F1-score provide a useful starting point, but a production-ready evaluation goes much deeper to uncover potential weaknesses that could have a significant business impact.
12.1 Beyond the Overall F1-Score
An aggregate F1-score can be dangerously misleading. A model might achieve an overall F1-score of 95% but be completely failing on a rare but critically important entity type. For example, in a medical context, failing to identify a rare but life-threatening "Adverse Drug Reaction" entity would be a catastrophic failure, even if the model performs perfectly on more common entities.
12.2 Entity-Level Metrics
To get a true picture of model performance, it is essential to calculate precision, recall, and F1-score for each entity type individually. This per-entity evaluation immediately highlights which categories the model is struggling with. If the "Product Name" entity has a low recall, it signals that more training examples for that specific entity are needed. This granular analysis is a standard feature in evaluation frameworks like Azure's custom NER service.
The core metrics are defined as follows:
Precision: Measures accuracy among the predictions made. Of all the entities the model predicted, how many were correct? Precision=TP+FPTP.
Recall: Measures completeness. Of all the actual entities in the text, how many did the model find? Recall=TP+FNTP.
F1-Score: The harmonic mean of precision and recall, providing a single balanced metric. F1Score=2×Precision+RecallPrecision×Recall.
Where TP = True Positives, FP = False Positives, and FN = False Negatives.
12.3 The Confusion Matrix
The confusion matrix is one of the most powerful diagnostic tools for an NER model. It is a matrix that visualizes the performance by showing not just if an error was made, but what kind of error. The rows typically represent the actual labels, and the columns represent the predicted labels.
By examining the off-diagonal cells, a developer can identify specific patterns of confusion. For example, if there is a high value at the intersection of the "Person" row and the "Organization" column, it means the model is frequently misclassifying people as organizations. This insight provides a direct, actionable path for model improvement: add more training examples that help the model distinguish between these two ambiguous entity types.
12.4 Evaluating on Business-Critical Slices
Overall metrics can also hide poor performance on specific, important subsets of the data. It is crucial to "slice" the evaluation dataset and analyze performance on these segments. For example, a model extracting information from invoices should be evaluated separately on invoices from high-value clients versus low-value clients. A model processing customer support tickets should be evaluated on tickets from different geographic regions or product lines. This approach connects model performance directly to business impact and can reveal biases or weaknesses that would otherwise go unnoticed.
12.5 Advanced Metrics
For mature production systems, more advanced evaluation techniques can provide even deeper insights:
Calibration: This assesses whether the model's confidence scores are trustworthy. A well-calibrated model that predicts an entity with 90% confidence should be correct 90% of the time. Calibration curves can be plotted to diagnose over- or under-confident models, which is critical for applications where confidence scores are used for decision-making.
Explainability (XAI): Tools like LIME and SHAP can be used to explain individual predictions. By analyzing which features or tokens contributed most to a specific correct or incorrect prediction, developers can gain a deeper understanding of the model's behavior and diagnose systematic errors.
Chapter 13: Deployment Architectures and Strategies
Deployment is the process of taking a trained model artifact and making it available to serve predictions in a live environment. The choice of deployment architecture has long-term implications for cost, scalability, security, and maintenance.
13.1 Containerization with Docker
The first step toward a modern, portable deployment is containerization. Using a tool like Docker, the model, its dependencies (e.g., Python libraries), and the inference code are all packaged into a single, self-contained unit called a container image. This image can then be run consistently across any environment—from a developer's laptop to a cloud server—eliminating "it works on my machine" problems.
13.2 Creating an Inference API with FastAPI
To make the model accessible to other applications, it needs to be wrapped in an API. A RESTful API is the standard approach. Python frameworks like Flask or FastAPI are excellent choices for this. FastAPI, in particular, is favored for its high performance, automatic generation of interactive API documentation, and modern features based on standard Python type hints. A simple FastAPI application would define an endpoint (e.g.,
/predict) that accepts text as input, passes it to the loaded NER model, and returns the extracted entities as a JSON response.
13.3 Cloud Deployment Patterns
Cloud platforms offer a wide range of managed services that simplify the deployment and scaling of ML models.
Azure AI Services: Azure provides a comprehensive suite for custom NER through its Language Studio. It offers a guided UI and a REST API for the entire lifecycle. A key feature is the ability to manage multiple deployments for a single project, such as a "staging" deployment for testing a new model and a "production" deployment for the stable, live model. The platform allows for easy "swapping" of these deployments, enabling safe, controlled rollouts of new model versions.
Google Cloud Vertex AI: GCP's unified ML platform, Vertex AI, provides a robust environment for deploying models. Models can be uploaded to the Vertex AI Model Registry and then deployed to a Vertex AI Endpoint. This endpoint handles the infrastructure, scaling, and request serving. Vertex AI supports deploying custom-trained models as well as models from its Model Garden. It offers fine-grained control over the underlying compute resources and autoscaling configurations.
AWS (Serverless): For cost-effective and highly scalable deployments, a serverless architecture using AWS Lambda is a powerful pattern. In this setup, the trained model artifacts are stored in an S3 bucket. An AWS Lambda function is created, which contains the inference code. When invoked, the Lambda function downloads the model from S3 (caching it for subsequent calls), processes the input, and returns the prediction. This approach eliminates the need to manage servers, as the infrastructure scales automatically with the number of requests.
13.4 On-Premise & Self-Hosted Deployment
For organizations with stringent data privacy, security regulations (like in healthcare or finance), or specific latency requirements, deploying on-premise or in a private cloud is necessary.
Using Elasticsearch: A powerful pattern for on-premise NER is to integrate it directly into an Elasticsearch cluster. Using Elastic's Eland tool, a Hugging Face NER model can be imported and deployed within Elasticsearch. This allows inference to be performed as part of an ingest pipeline, meaning documents are automatically enriched with named entities as they are indexed. This makes the entities immediately available for search, aggregation, and analysis within Kibana, creating a tightly integrated data processing and search solution.
General On-Premise Strategy: A more general approach involves setting up and managing the entire infrastructure stack internally. This includes provisioning servers (physical or virtual), installing the necessary software, and using container orchestration platforms like Kubernetes to manage and scale the deployed Docker containers. This provides maximum control but also entails the highest maintenance overhead.
The choice between cloud and on-premise deployment is a major strategic decision. The following table highlights the key factors to consider.

Chapter 14: Monitoring, Retraining, and Continuous Improvement
Deploying a model is the beginning, not the end, of its lifecycle. A model's performance in the real world is not static; it will inevitably degrade over time as the data it encounters in production drifts away from the data it was trained on. Production monitoring is the practice of observing the model's behavior to detect this degradation before it negatively impacts the business, and a retraining pipeline is the mechanism to correct it.
14.1 Why Production Monitoring is Non-Negotiable
Validation results from a static test set are a snapshot in time. They do not guarantee future performance. The real world is dynamic; language evolves, new products are launched, and user behavior changes. This phenomenon is known as model drift, and it is the primary reason why continuous monitoring is essential for any production ML system.
14.2 Types of Monitoring
A comprehensive monitoring strategy covers both the operational health of the system and the functional quality of the model's predictions :
Operational Monitoring: This focuses on traditional software system metrics. Is the API responding? What is the request latency? What is the CPU/GPU utilization? Are there any system errors (e.g., 500 status codes)? These metrics ensure the service is available and performant.
Functional Monitoring: This focuses on the data and the model's predictions. Is the input data quality consistent? Is the model's performance degrading? This type of monitoring is specific to ML systems.
14.3 Detecting Model Drift
Detecting drift is the core goal of functional monitoring. There are two primary types of drift to watch for :
Data Drift (or Feature Drift): This occurs when the statistical properties of the input data change over time. For an NER model, this could mean a shift in the average length of documents, the vocabulary used, or the introduction of new formats. Data drift is a powerful leading indicator; if the input data is changing, the model's performance is likely to degrade soon.
Concept Drift: This is a more direct problem where the relationship between the input data and the correct output labels changes. For NER, this could happen if a word's meaning evolves (e.g., a new company is founded with a common name) or if the business decides to start tracking a new entity type. Concept drift directly impacts model accuracy.
A critical challenge in monitoring NER models is that the ground truth (i.e., human-verified labels for production data) is often not available in real-time. It may arrive with a significant delay or only for a small sample of data. This makes it difficult to directly monitor precision and recall.
In the absence of immediate ground truth, it is necessary to rely on proxy metrics that correlate with model performance. One of the most powerful strategies for NER is to monitor the statistical properties of the model's output. Drastic changes in the distribution of predictions are a strong signal that something is wrong. Key proxy metrics to monitor include:
Distribution of Predicted Entity Labels: Track the percentage of entities identified for each category (e.g.,
PERSON,ORG,LOC). If a model that normally identifies 10% of entities asORGsuddenly starts identifying 50%, it indicates a potential issue with either the input data or the model itself.Entity Count per Document: Monitor the average number of entities the model finds in each document. A sudden spike or drop in this number suggests a change in behavior.
Null Response Rate: Track the percentage of documents for which the model identifies zero entities. If this rate changes significantly, it could mean the model is failing on a new type of input data.
By setting up dashboards and alerts based on these proxy metrics, a team can create an effective early warning system to detect model degradation long before the delayed ground truth becomes available.
14.4 The Retraining Pipeline
When monitoring detects significant drift or performance degradation, the model must be retrained. A robust retraining pipeline is an automated or semi-automated workflow for updating the production model.
Triggering Retraining: Retraining can be triggered on a fixed schedule (e.g., re-train the model every month) or dynamically when monitoring alerts fire (e.g., re-train when the F1-score on a validation set drops below a predefined threshold).
Data for Retraining: The new training dataset should be a combination of the original training data and a fresh set of labeled data collected from the production environment via the feedback loop. This ensures the model learns from the most recent data patterns while not forgetting past knowledge.
Shadow & A/B Testing: A newly retrained model should never be deployed directly to production. It must first be validated to ensure it is actually an improvement over the current model.
Shadow Mode: The new model is deployed alongside the production model. It receives the same live traffic but its predictions are only logged and not returned to the user. This allows for a direct comparison of the two models' performance on real-world data without any user impact.
A/B Testing: A small percentage of live traffic is routed to the new model, and its performance (both model metrics and business KPIs) is compared to the existing model. If the new model proves superior, traffic is gradually shifted until it is serving 100% of requests.
This cycle of monitoring, retraining, and safe deployment ensures that the NER system remains accurate and valuable over its entire lifetime.
Part VI: Realizing Value: Case Studies and Strategic Implementation
The ultimate goal of any technical endeavor in a business context is to create value. A production-grade NER system, built with engineering discipline and data-centric principles, can be a transformative asset across a wide range of industries. This final part explores concrete examples of how NER drives business value and provides a concluding outlook on the future of the field.
Chapter 15: NER in Action: Industry Case Studies
The applications of NER are broad and impactful, enabling organizations to automate processes, gain deeper insights from their data, and improve customer experiences. By extracting structured information from unstructured text, NER unlocks the value hidden in documents, emails, social media, and more.
15.1 Finance and Financial Services: The financial industry is awash in unstructured text, from news articles and social media to lengthy regulatory filings and loan agreements. NER is used to:
Extract Structured Data: Automatically parse company names, financial figures (e.g., revenue, profit), and other key data points from earnings reports and PDFs to speed up content collection and analysis.
Accelerate Risk Assessment: In private markets and lending, NER can extract relevant information from documents to aid in assessing credit risk and profitability, a process that is otherwise slow and prone to human error.
Monitor Market Trends: Track mentions of companies, people, and stocks on social media platforms like Twitter and Reddit to identify emerging trends and sentiment shifts that can drive market movements.
15.2 Human Resources (HR) and Recruitment: NER is a key technology for making HR processes more efficient and data-driven.
Automated Resume Parsing: NER models can automatically scan resumes and CVs to extract key information such as candidate names, skills, degrees, and past job titles. This dramatically speeds up the initial screening and candidate matching process.
Employee Feedback Analysis: By extracting entities from performance reviews and employee feedback surveys, HR departments can categorize comments, track sentiment, identify top performers, and pinpoint areas for workplace improvement.
15.3 Legal and Compliance: The legal sector relies heavily on the analysis of dense, lengthy documents. NER provides a powerful tool for automation.
Contract Analysis: Automatically identify and extract critical entities such as party names, jurisdictions, effective dates, and specific contract clauses, reducing the time and cost of manual review.
Enhanced E-Discovery: During litigation, NER can scan vast volumes of electronic information (emails, documents) to identify relevant entities, speeding up the process of finding crucial evidence and reducing manual review efforts.
Patent Analysis: In intellectual property law, NER can automate the extraction of inventors, assignees, and key technical details from patent documents, accelerating patent prosecution and strategic analysis.
15.4 Supply Chain and Logistics: Efficiency in the supply chain depends on accurate and timely information.
Optimizing Logistics: NER can process textual data from purchase orders, invoices, and bills of lading to extract product names, quantities, supplier details, and delivery locations. This structured data enables real-time inventory tracking, demand forecasting, and improved shipment route planning.
15.5 Customer Support and Marketing: Understanding the voice of the customer is crucial for any business.
Efficient Customer Support: NER can analyze incoming customer inquiries from emails, chats, and support tickets to automatically identify the product in question, the reported issue, and other key details. This enables automated categorization and routing of tickets to the correct team, improving response times.
Targeted Marketing and Brand Monitoring: By analyzing social media posts, reviews, and forums, marketers can use NER to identify mentions of their brand, competitors, relevant trends, and consumer opinions. This helps in gauging campaign effectiveness, understanding customer sentiment, and identifying potential influencers for collaboration.
Content Recommendation: NER can power recommendation engines by extracting entities from articles or products a user has engaged with and then recommending other content that mentions similar entities.
Chapter 16: Conclusion and Future-Forward Outlook
The journey from a basic concept to a production-grade NER system is a multifaceted endeavor that blends data science, software engineering, and project management. This handbook has charted that course, providing a comprehensive roadmap for developers looking to master this powerful technology.
16.1 The End-to-End Journey Recapped
The central themes woven throughout this guide converge on a few core principles for success:
Success is Built on Data and Discipline: The most advanced model architecture cannot compensate for poor-quality data or a chaotic development process. The success of a custom NER project is primarily determined by the investment in high-quality, consistent data annotation and the adherence to a structured project management lifecycle.
The Right Model is a Strategic Trade-off: There is no universally "best" model. The choice between a fine-tuned Transformer, a generative LLM, or a custom spaCy model is a strategic decision that must balance the competing demands of performance, cost, latency, and complexity for the specific use case.
Production is a Cycle, Not a Destination: A deployed model is not a finished product. The work of MLOps—monitoring, maintenance, and retraining—is what separates a fragile prototype from a robust, long-lived production service. The most successful systems are designed from the outset as continuous feedback loops that learn and improve over time.
16.2 The Future of NER
The field of Named Entity Recognition continues to evolve at a rapid pace. Several emerging trends are set to shape the next generation of NER systems, making them more powerful, accessible, and transparent.
Zero-Shot and Few-Shot Learning: The capabilities of large language models to perform tasks with minimal or no specific training examples will continue to improve. This will further reduce the burden of data annotation, allowing for the rapid development of NER systems for new domains and entity types with unprecedented speed.
Explainable AI (XAI) for NER: As NER is increasingly deployed in high-stakes domains like healthcare and finance, the demand for transparency and interpretability will grow. Techniques that can explain why a model made a particular prediction will become crucial for building trust, debugging models, and ensuring fairness and compliance.
Graph-Based NER and Entity Linking: The future of information extraction lies not just in identifying entities, but in understanding their relationships. NER systems will become more tightly integrated with knowledge graphs. The task will evolve from simply labeling "Apple" as an
ORGto linking it to a canonical node in a knowledge graph that contains rich information about the company, its products, and its executives. This will enable a deeper, more connected understanding of text.The Continued Convergence of NER and LLMs: The line between specialized NER models and general-purpose LLMs will continue to blur. As LLMs become more efficient and open-source models become more powerful, developers will have an even broader spectrum of tools at their disposal. The future may lie in hybrid systems that leverage the broad knowledge of LLMs for complex reasoning and entity linking, while using smaller, highly optimized models for high-throughput, low-latency extraction tasks.
By mastering the end-to-end principles outlined in this guide, developers will be well-equipped not only to build the powerful NER systems of today but also to innovate and lead in the exciting future of this foundational NLP technology.