
From Model to Production: The Ultimate AI Developer's Field Manual (MLOps Edition)
It’s Not About the Model. It’s About the System.

Welcome to The Developer’s AI Production Field Manual—your one-stop guide to deploying AI at scale. This episode breaks down the shift from model-centric thinking to a system-focused AI mindset, emphasizing the critical role of MLOps in modern production pipelines.
We explore:
How to design robust data ingestion & prep systems
Best practices for model validation before deployment
Production deployment strategies that actually work
Continuous monitoring, feedback loops, and performance maintenance
Build vs Buy: When to leverage open source and when to go custom
If you're serious about building real-world AI products that scale, this is the playbook you’ve been waiting for.
✅ Subscribe for weekly GenAI deep dives.
💬 Drop your favorite open-source AI tools in the comments!
#AIProductionPlaybook
The Developer's Field Manual to Production-Ready AI: An End-to-End Guide
Introduction: Beyond the Notebook — Adopting the Production Mindset
The journey of creating an Artificial Intelligence solution often begins in the familiar confines of a Jupyter Notebook, a space where algorithms are born and accuracy metrics are king. However, the true test of an AI's value lies far beyond this development sandbox. A successful AI is not merely a high-performing model; it is a robust, reliable, and maintainable
system that delivers continuous value within a live production environment. This distinction marks the critical shift from a model-centric to a system-centric approach, a transition that is fundamental for any developer aiming to build production-grade AI.
An "End-to-End AI solution" is a coherent, integrated system that encompasses the entire project lifecycle, from initial data collection and processing to model development, deployment, and ongoing monitoring. This approach stands in stark contrast to relying on a patchwork of disparate systems, instead favoring a unified infrastructure or platform that coordinates all stages of the process. The paradigm that enables this holistic view is Machine Learning Operations (MLOps). MLOps is the application of DevOps principles to the unique challenges of the machine learning lifecycle, emphasizing automation, collaboration, and continuous iteration. It is a philosophy that transforms the AI development process from a linear, one-off task into a dynamic, cyclical system.
This evolution in thinking is not just academic; it is a reflection of how leading technology companies operate. The focus of engineering efforts at firms like Uber and Netflix is not just on algorithms, but on building comprehensive platforms like Michelangelo and Metaflow that manage the entire end-to-end lifecycle. The model, while central, is just one component of a much larger system that includes data pipelines, automated testing infrastructure, deployment mechanisms, and monitoring dashboards. Consequently, the most valuable skill for a production AI developer is not just algorithmic expertise but a strong foundation in systems engineering.
This report provides a developer-focused field manual for building such systems, structured around four core phases: Data Ingestion and Preparation, Model Development and Validation, Deployment, and Monitoring. By navigating these stages with a production-first mindset, developers can build AI solutions that are not only intelligent but also resilient and impactful.
Phase 1: Architecting the Foundation — Data Ingestion and Preparation
The foundation of any AI system is its data. This initial phase of the lifecycle, which involves acquiring and preparing data, is frequently the most time-consuming and critical stage. The quality of the final model is directly constrained by the quality of the input data; poor or incomplete data is a primary driver of model failure in production.
Building the Data Backbone: Ingestion Strategies
Data ingestion is the process of discovering, preparing, and moving data from a multitude of sources into a system where it can be used for analysis and model training. The chosen strategy depends heavily on the data's source, volume, and velocity.
Batch Ingestion: This method involves processing data in large, scheduled blocks. It is ideal for analytics and model training scenarios where real-time updates are not necessary and latency is not a primary concern. Data can be ingested from files or databases.
File-based (CSV):
Python
import pandas as pd
# Read a CSV file into a Pandas DataFrame
df = pd.read_csv('your_data.csv')
Database (PostgreSQL):
Python
from sqlalchemy import create_engine
import pandas as pd
# Connect to a PostgreSQL database
engine = create_engine('postgresql://user:pass@host:port/db')
# Query and load data into a Pandas DataFrame
df = pd.read_sql_query('SELECT * FROM your_table', engine)
Real-Time & Streaming Ingestion: This approach involves the continuous collection and processing of data as it is generated. It is crucial for use cases that require immediate action, such as fraud detection, real-time personalization, or IoT sensor analysis.
Streaming (Apache Kafka):
Python
from confluent_kafka import Consumer
# Configure Kafka Consumer
consumer_conf = {'bootstrap.servers': 'your_kafka_broker', 'group.id': 'mygroup'}
consumer = Consumer(consumer_conf)
consumer.subscribe(['your_topic'])
# Poll for new messages
while True:
msg = consumer.poll(1.0)
if msg is not None and msg.error() is None:
print(f"Received message: {msg.value().decode('utf-8')}")
API Integration & Web Scraping: Many applications require data from external web services or websites. This can be achieved by calling APIs or, when an API is unavailable, by scraping HTML content.
API Integration:
Python
import requests
# Make a GET request to an API endpoint
response = requests.get('https://api.example.com/data')
data = response.json()
Web Scraping:
Python
from bs4 import BeautifulSoup
import requests
# Make an HTTP request and parse HTML
response = requests.get('https://example.com')
soup = BeautifulSoup(response.text, 'html.parser')
# Extract specific data from the HTML
data = soup.find('div', class_='your_class').text
Cloud-Based Ingestion: Cloud storage platforms like Amazon S3 or Google Cloud Storage (GCS) often serve as a centralized data lake, providing a scalable and durable source for data ingestion.
Cloud Storage (GCS):
Python
from google.cloud import storage
# Create a client and access the bucket
client = storage.Client()
bucket = client.get_bucket('your-bucket-name')
# Download a file from Cloud Storage
blob = bucket.blob('your-file.csv')
blob.download_to_filename('local_file.csv')
To aid in selecting the appropriate method, the following table provides a comparative overview.
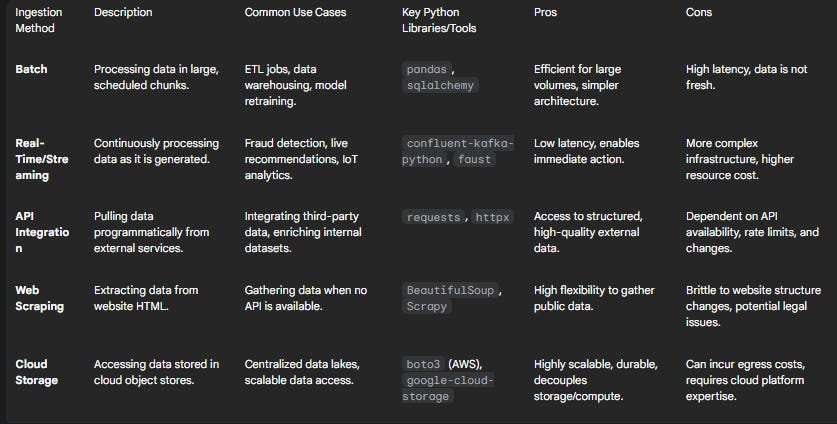
The Art of Data Transformation: Preprocessing & Feature Engineering
Raw data is almost never suitable for direct use in machine learning models. The process of transforming this raw input into clean, structured features is known as data preprocessing and feature engineering. This step is not merely about cleaning; it is about sculpting the data to reveal the underlying patterns that a model can learn.
Data Cleaning: This involves addressing imperfections in the data. Common tasks include handling missing values, either by removing the affected records or by imputing them using statistical measures like the mean, median, or mode. It also includes identifying and handling outliers, which are data points that deviate significantly from others and can skew model training.
Data Transformation & Scaling: Algorithms often perform better when numerical features are on a similar scale.
Normalization (Min-Max Scaling) scales features to a fixed range, typically . This is useful for algorithms like neural networks that are sensitive to the scale of input features.
Standardization (Z-score Scaling) transforms features to have a mean of 0 and a standard deviation of 1. It is less affected by outliers than normalization and is a common requirement for many linear models.
Log Transformation is effective for handling data with a skewed distribution, making it more symmetric.
Encoding Categorical Variables: Machine learning models require numerical input. Categorical data (e.g., 'country', 'product_category') must be converted into a numerical format.
One-Hot Encoding creates a new binary column for each category, avoiding any implied ordering.
Label Encoding assigns a unique integer to each category, which is suitable for ordinal variables where a natural order exists.
Advanced Feature Engineering: This is where domain knowledge and creativity can significantly boost model performance. It involves creating new, more informative features from the existing data.
Binning/Discretization: Grouping a continuous variable into a set of "bins" can help capture non-linear relationships. For instance, 'age' can be binned into categories like '0-18', '19-35', etc..
Interaction Features: Combining two or more features can capture their synergistic effect. For example, in a housing price model, dividing
pricebysquare_footagecreates a highly predictiveprice_per_sq_ftfeature.Time-Based Features: For time-series data, extracting components like 'day of the week', 'month', or 'is_weekend' from a timestamp can reveal cyclical patterns.
A crucial realization for production-focused developers is that this preprocessing workflow is not a disposable script run once in a notebook. To make predictions on new, unseen data in production, that data must undergo the exact same transformation steps as the training data. Any discrepancy between the features used for training and those used for serving (a problem known as training-serving skew) will cause model performance to degrade silently and catastrophically.
Therefore, the entire sequence of preprocessing steps must be captured and saved as a reusable, versioned production artifact. The Pipeline object from the scikit-learn library is an excellent tool for this. It chains together multiple transformation steps (e.g., imputation, scaling, encoding) into a single object. This pipeline is then fitted on the training data and saved (serialized) using a library like joblib or pickle. In production, this same saved pipeline object is loaded to transform incoming prediction requests, guaranteeing consistency and preventing skew. This practice elevates preprocessing from a mere data cleaning exercise to the construction of a core, deployable component of the final application.
Governance and Versioning: Treating Data and Features as Code
A core tenet of MLOps is reproducibility. To achieve this, not only code but also data and the features derived from it must be versioned.
Data Lineage: It is essential to maintain a clear record of data lineage—tracking where data comes from and the transformations it undergoes. This is vital for debugging, auditing, and ensuring regulatory compliance.
Data Version Control (DVC): Tools like DVC integrate with Git to version large data files, models, and intermediate artifacts without bloating the code repository. This allows developers to tie specific versions of data to specific versions of code, making experiments fully reproducible.
Feature Stores: As ML systems scale, a feature store becomes invaluable. It is a centralized repository for storing, managing, and serving features for both model training and real-time inference. Platforms like Uber's Michelangelo rely on feature stores to ensure that the features used to train a model are identical to those used for prediction, thereby solving the training-serving skew problem at scale.
Phase 2: The Core Intelligence — Model Development and Validation
This phase transitions from data preparation to creating the core intelligence of the system. It is a highly iterative cycle of experimentation, training, and, most importantly, rigorous validation to ensure the model is not only accurate but also reliable and fair.
Algorithm Selection and Architecture
Choosing the right model is not always about selecting the most complex or state-of-the-art algorithm. Practical considerations often dictate a more pragmatic approach.
Analyzing Trade-offs: A critical task is to balance the trade-offs between model complexity, interpretability, computational cost, and performance. For instance, in highly regulated domains like finance or healthcare, a simpler, more interpretable model like logistic regression or a decision tree might be preferable to a "black box" deep learning model, even at the cost of a slight dip in accuracy. Uber, for example, initially used tree-based models like XGBoost for many of its critical prediction tasks before gradually adopting more complex deep learning solutions where appropriate.
Systematic Experiment Tracking: The experimental nature of model development means that teams will test numerous combinations of algorithms, data subsets, and hyperparameters. It is essential to track these experiments systematically. Tools like MLflow and Neptune.ai allow developers to log the parameters, code versions, data versions, and resulting metrics for every run. This practice ensures reproducibility and prevents valuable experimental results from being lost.
The Iterative Training and Tuning Loop
Once a candidate architecture is chosen, the model enters a loop of training and refinement.
Data Splitting: The dataset must be correctly partitioned into training, validation, and testing sets. The training set is used to teach the model, the validation set is used to tune hyperparameters and make architectural decisions, and the test set is held out until the very end to provide an unbiased evaluation of the final model's ability to generalize to new, unseen data.
Hyperparameter Tuning: Most models have hyperparameters (settings that are not learned from the data, such as the learning rate in a neural network) that need to be optimized. Techniques like Grid Search, which exhaustively tries all combinations of specified parameters, and Randomized Search, which samples them randomly, are common methods for finding the optimal configuration.
Cross-Validation: To obtain a more robust estimate of a model's performance and to mitigate the risk of overfitting to a particular validation set, k-fold cross-validation is used. This technique involves splitting the training data into 'k' subsets, training the model 'k' times on k-1 folds, and evaluating it on the remaining fold each time. The final performance is the average of the results from all 'k' trials.
Beyond Accuracy: A Multi-faceted Approach to Model Evaluation
Relying on a single performance metric, such as accuracy, can be dangerously misleading. A model can achieve high accuracy but be practically useless or even harmful. For example, a fraud detection model that simply predicts "not fraud" for every transaction may be 99.9% accurate if fraud is rare, but it fails at its primary task.
Comprehensive Classification Metrics: For classification problems, a confusion matrix is the starting point for a deeper evaluation. It allows for the calculation of:
Precision: Of all the positive predictions, how many were actually correct? High precision is critical when the cost of a false positive is high (e.g., flagging a legitimate email as spam).
Recall (Sensitivity): Of all the actual positive cases, how many did the model correctly identify? High recall is vital when the cost of a false negative is high (e.g., failing to detect a cancerous tumor).
F1-Score: The harmonic mean of precision and recall, providing a single metric that balances both concerns.
Regression Metrics: For regression tasks that predict a continuous value, common metrics include Root Mean Squared Error (RMSE) and Mean Absolute Error (MAE), which measure the average magnitude of the errors.
Segment-Based Evaluation: This is a crucial and often overlooked step for building responsible AI. Overall metrics can hide poor performance on specific, important subgroups within the data. It is imperative to evaluate the model's performance on critical data segments, such as different demographic groups, geographic regions, or user types. This analysis can uncover hidden biases and ensure the model performs equitably and reliably for all users.
The process of building and validating an ML model requires a testing philosophy that extends beyond traditional software engineering practices. While conventional software testing focuses on functional correctness through unit and integration tests, ML systems introduce new, non-deterministic failure modes. A model can be functionally perfect—it takes an input and produces an output without crashing—but be logically flawed, generating incorrect, biased, or nonsensical predictions. Therefore, the validation process for an ML system is a superset of traditional software testing. It must include all the standard unit and integration tests for the code components (e.g., the feature pipeline, the API endpoint) , but it must also incorporate a new layer of testing that treats data and model behavior as first-class citizens. This includes automated data validation checks, model quality validation against established performance thresholds, and rigorous testing for fairness and bias across different data segments. Teams cannot simply port their existing CI/CD testing frameworks; they must adopt this more comprehensive validation methodology to ensure the production-readiness of their AI systems.
Phase 3: From Lab to Live — Production Deployment Strategies
Deployment is the process of taking a trained and validated model and integrating it into a production environment where it can serve predictions to end-users or other systems. This is the stage where the model begins to deliver tangible value.
Packaging and Serving: APIs, Containers, and Microservices
The first step in deployment is to package the model into a self-contained, executable unit that can be easily managed and called upon.
Model Serialization: The trained model object, along with its associated preprocessing pipeline, must be saved to a file. This process, known as serialization, is commonly done using Python libraries like
jobliborpickle. This creates a persistent artifact that can be loaded into any Python environment without needing to retrain the model.Creating a Prediction Service via REST API: To make the model accessible to other applications, it is typically wrapped in a web server and exposed via a REST API. Lightweight Python web frameworks like Flask and
FastAPI are popular choices. A developer would create an endpoint (e.g.,
/predict) that accepts input data in a standard format like JSON, loads the serialized model, transforms the input using the saved pipeline, generates a prediction, and returns the result.Containerization with Docker: A critical best practice is to containerize the prediction service using Docker. A
Dockerfilespecifies all the components needed to run the application: the base operating system, Python version, required libraries, application code, and the serialized model files. This creates a lightweight, portable, and self-sufficient container image. Containerization guarantees that the application runs identically regardless of the environment—be it a developer's laptop, a staging server, or a production cluster—thus eliminating "it works on my machine" problems. A sampleDockerfilemight look like this:Dockerfile
# Use an official Python runtime as a parent image
FROM python:3.9-slim
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file and install dependencies
COPY requirements.txt requirements.txt
RUN pip install --no-cache-dir -r requirements.txt
# Copy the rest of the application code and the model
COPY./app /app
COPY./model /app/model
# Expose the port the app runs on
EXPOSE 8000
# Define the command to run the application
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8000"]
Microservices Architecture: By containerizing the model and exposing it via an API, it effectively becomes a microservice. This architectural pattern allows the ML service to be developed, deployed, updated, and scaled independently of the larger application it serves, promoting agility and resilience.
Orchestrating at Scale: The Role of Kubernetes and CI/CD
While Docker is excellent for packaging a single service, managing and scaling many containers in production requires a container orchestration platform.
Container Orchestration with Kubernetes: Kubernetes has become the industry standard for orchestrating containerized applications. It automates the deployment, scaling, and management of containers, providing critical capabilities for MLOps, including automated scaling based on traffic, zero-downtime rolling updates for new model versions, and self-healing to automatically restart failed containers.
CI/CD for Machine Learning: Continuous Integration/Continuous Deployment (CI/CD) is the engine of MLOps automation. A CI/CD pipeline automates the entire workflow, from a code change in a repository to the deployment of a new model in production. The ML-specific CI/CD pipeline differs from a traditional software pipeline in a few key ways :
Trigger: A pipeline run can be triggered not only by a change in code but also by a change in the underlying data.
Testing: The testing stage is expanded. In addition to standard unit and integration tests, it must include data validation tests and model performance evaluation against predefined thresholds.
Continuous Training (CT): The pipeline often includes a step to automatically retrain the model on new data.
Deployment: The final artifact being deployed is not just application code but a versioned model served via a containerized API.
A conceptual ci.yml file for a service like GitHub Actions might illustrate these stages, automating the build, comprehensive testing, and deployment of the model service.
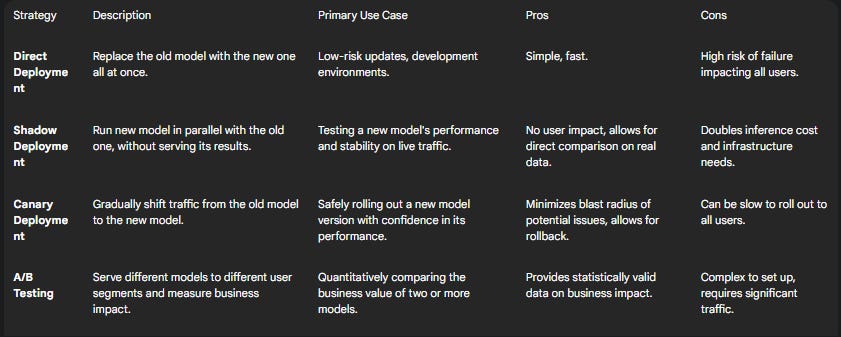
Advanced Deployment Patterns: Canary, Shadow, and A/B Testing
Deploying a new model directly to 100% of production traffic is risky. Advanced deployment strategies are used to mitigate this risk by gradually and safely rolling out changes.
Shadow Deployment: The new model is deployed alongside the existing production model. Live traffic is sent to both models, but only the predictions from the old model are served to users. The new model's predictions are logged and compared against the old one's, allowing for performance validation on real-world data without any user impact.
Canary Deployment (Gradual Rollouts): The new model is initially released to a small subset of users (e.g., 5% of traffic). Its performance is monitored closely for key metrics like error rates and business impact. If it performs as expected, traffic is gradually shifted from the old model to the new one until the rollout is complete.
A/B Testing: This is a more formal, scientific approach where different model versions are deployed simultaneously to distinct user groups. The impact of each model on key business metrics (e.g., click-through rate, conversion rate) is measured statistically to determine which version is superior.
The following table compares these strategies to help developers select the most appropriate pattern.
Phase 4: The Vigilant Guardian — Monitoring and Maintaining Production Models
Deploying a model is not the final step; it is the beginning of its operational life. Models are not static entities; their performance inevitably degrades over time as the real world changes. Continuous monitoring is therefore essential to detect and mitigate this degradation, ensuring the model remains effective and reliable.
Detecting Drift: The Silent Model Killer
Model degradation, or "drift," is the primary reason that production models require vigilant monitoring. It typically manifests in two forms:
Data Drift: This occurs when the statistical properties of the input data in production change over time, diverging from the data the model was trained on. For example, a loan application model trained on pre-pandemic economic data may perform poorly when it encounters applications reflecting new post-pandemic economic realities. The model is seeing data patterns it has never encountered before, leading to unpredictable and often inaccurate predictions.
Concept Drift: This is a more fundamental change where the relationship between the input features and the target variable itself evolves. For instance, in an e-commerce recommendation system, user preferences and purchasing habits can shift due to new trends or seasonal events. The underlying patterns the model learned are no longer valid, even if the input data distribution remains the same.
Drift is detected by continuously comparing the distribution of live production data against a stable baseline, typically the training dataset. This can be done by tracking summary statistics (mean, median, standard deviation) of features or by using statistical tests like the Kolmogorov-Smirnov (KS) test to detect significant distributional shifts.
Closing the Loop: Automated Retraining and Continuous Improvement
Monitoring is not merely an observational activity; its purpose is to trigger corrective action. This is where the concept of
Continuous Training (CT) becomes a cornerstone of MLOps. CT is the practice of automatically retraining models to adapt to a changing environment.
A retraining pipeline can be triggered by several events:
On a fixed schedule (e.g., daily, weekly).
Upon detection of significant data or concept drift.
When model performance metrics drop below a predefined threshold.
When a sufficient amount of new labeled data becomes available.
This automated process creates a crucial feedback loop, allowing the AI system to learn from new data and continuously adapt to its environment, thereby maintaining its accuracy and relevance over time.
The Full Picture: Holistic Performance Monitoring
A comprehensive monitoring strategy must encompass a hierarchy of metrics that provide a complete view of the system's health, from its technical performance to its business impact.
Model Quality Metrics: These metrics track the model's core predictive performance. This involves capturing the model's predictions in production and, when ground truth data becomes available, joining them to calculate metrics like accuracy, precision, recall, or F1-score. This process can have a delay, as ground truth is often not available in real-time.
Data Quality Metrics: This layer monitors the health of the input data itself. It tracks for issues like an increase in null values, schema changes (e.g., a feature is no longer being sent), or values falling outside expected ranges. Poor data quality is often a leading indicator of downstream model problems.
Operational Metrics (Software Health): These metrics track the performance of the serving infrastructure. This includes monitoring the API's latency (how quickly it responds to requests), throughput (queries per second, or QPS), error rates, and the resource utilization of the containers (CPU, memory, disk I/O).
Business KPIs: Ultimately, an AI model is deployed to achieve a business objective. It is essential to monitor how the model's predictions affect key business metrics. For a recommendation engine, this could be click-through rate or items added to cart. For a fraud detection model, it could be the value of fraudulent transactions prevented. This connects the model's technical performance directly to its business value.
The following table outlines a template for a comprehensive monitoring dashboard.

The Platform Question: Build vs. Buy and the Power of Open Source
With a clear understanding of the end-to-end lifecycle, a fundamental strategic question arises: should an organization build its own AI platform from scratch, or buy a pre-built solution? This decision has long-term implications for cost, speed, and flexibility.
The Strategic Crossroads: Building a Custom Platform vs. Buying a Solution
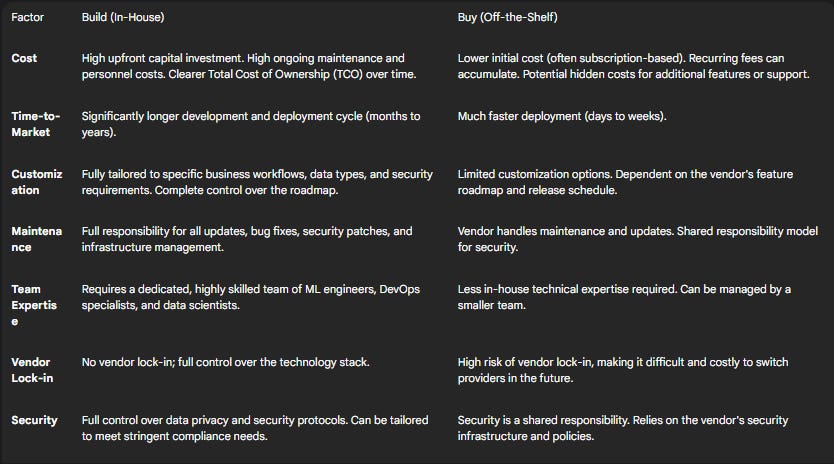
The "build vs. buy" decision is a common and complex dilemma for organizations embarking on their AI journey.
Reasons to Buy: Opting for an off-the-shelf solution generally offers a faster time-to-market, a lower initial investment, and reduced ongoing maintenance overhead. This path is often suitable for organizations with less in-house infrastructure expertise or those looking to quickly validate an AI use case.
Reasons to Build: Building a custom platform provides complete control and customization to meet specific business requirements and security standards. It avoids vendor lock-in and allows for seamless integration with existing internal systems. This approach is typically favored by more mature organizations with unique needs and the engineering resources to support a long-term development effort.
The Total Cost of Ownership (TCO): The decision must not be based on initial price alone. Building a platform requires a significant and continuous investment in a dedicated engineering team for development, maintenance, and upgrades. Buying a solution involves recurring subscription fees, and organizations can face high switching costs and limited flexibility due to vendor lock-in.
The Hybrid Approach: In practice, most organizations adopt a "buy-and-build" strategy. They construct a custom platform by integrating a combination of best-of-breed open-source and commercial tools, leveraging pre-built components for common tasks (like experiment tracking or monitoring) while building custom logic for their unique business needs.
The following table provides a strategic comparison to guide this decision.
Fueling the Engine: The Indispensable Role of Open Source
Regardless of the build-versus-buy decision, open-source software is the undeniable foundation of the modern AI ecosystem. The entire lifecycle described in this report is powered by a stack of open-source tools.
Innovation and Democratization: Open source accelerates innovation through global collaboration and peer review. It lowers the barrier to entry, democratizing access to powerful AI technologies and allowing more developers and organizations to participate.
Transparency and Trust: Open-source models and tools offer greater transparency than proprietary "black box" systems. This allows for community-driven scrutiny, which helps to identify and mitigate potential safety issues, security vulnerabilities, and inherent biases.
The Open-Source AI Stack: The end-to-end workflow relies heavily on open-source libraries at every stage:
Data Ingestion & Preparation:
pandas,NumPy,scikit-learnModel Development:
scikit-learn,PyTorch,TensorFlowDeployment:
Flask,FastAPI,Docker,KubernetesMonitoring & Orchestration:
MLflow,Prometheus
This reliance demonstrates that even when "buying" a platform, an organization is often purchasing a managed and integrated version of these fundamental open-source components.
Conclusion: Embracing the End-to-End Mindset
The path to production-ready AI is a journey of shifting perspectives—from focusing on a model's accuracy in isolation to architecting a complete, resilient, and automated system. True success in artificial intelligence is not achieved at the moment a model is trained, but through the continuous, reliable value it delivers in a dynamic production environment. This requires a holistic, end-to-end mindset that treats the entire lifecycle as a single, integrated system.
The principles of MLOps provide the necessary framework for this approach, championing automation, iterative development, and rigorous monitoring. By embracing these practices, developers move beyond the role of model builders to become systems engineers. They learn to treat data and features as versioned artifacts, to build preprocessing pipelines that are as critical as the model itself, to expand testing to include data and model validation, and to create feedback loops that allow systems to adapt and improve over time.
Ultimately, building a successful AI solution is a discipline that marries data science with robust software engineering. The call to action for every developer in this field is to look beyond the notebook, understand the full lifecycle, and adopt the system-centric principles required to build AI that is not just clever, but truly valuable and enduring.